cs285-lec10-optimal control and planning
Summary
Model-based Reinforcement Leanring
learn the transition probability, then figure out how to choose actions.
Terminology
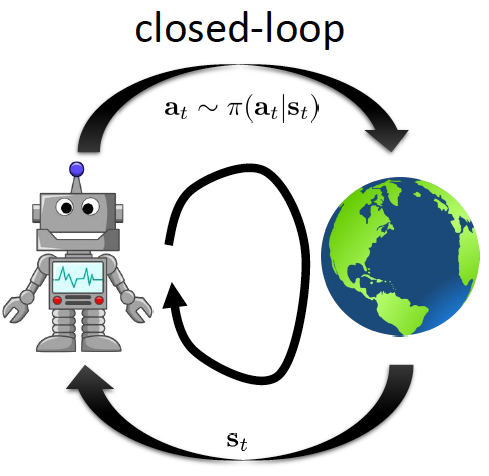
closed-loop: agents take one action per state.
open-loop: agents take all actions once receiving a state.
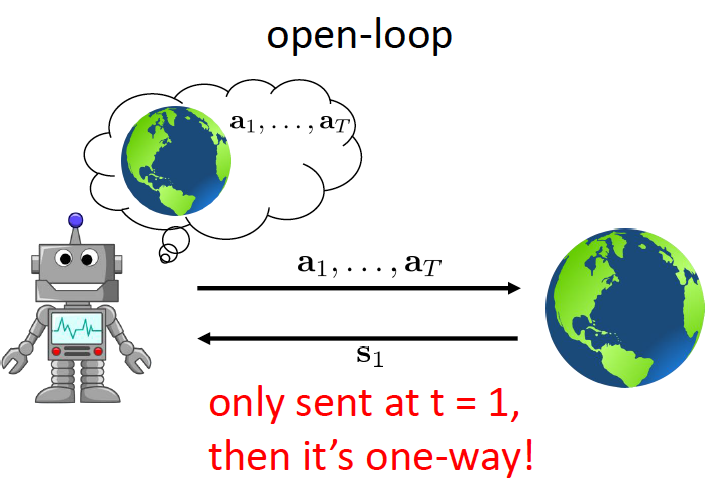
Open-loop Planning
Random Shooting Method
Let’s say is some method to evaluate the rewards we could get, and is the action set. Then the objective of optimal planning is:
So the random shooting method is simply guess & check:
- pick from some distribution (eg: uniform)
- choose based on
Advantage: efficient (could evaluate in parallel), simple
Disvantage: might not take good actions
Cross-entropy Method (CEM)
Improve the step1 in Random Shooting Method, use better distribution to pick
- sample from
- evaluate
- select the elites that have highest value, where
- refit to the elites
repeat this process until some condition.
Ususally we use Gaussian Distribution to start.
Advantage & Disadvantage about RSM and CEM
Advantage: fast if run in parallel, and very simple
Disvantage: could only work when dimension is small (no more than 30~60), only work for open-loop planning
Monte Carlo Tree Search (MCTS)
Discreate planning, MCTS runs as follows:
- find a leaf using TreePolicy()
- evaluate the leaf using DefaultPolicy()
- update all values between
repeat the above process and take the best action from
Usually the TreePolicy is UCT TreePolicy: if is not fully expanded, choose new , otherwise choose child with best
We calculate by:
MCTS is used mostly in board games like chess etc.
Trajectory Optimization with Derivatives
TBC