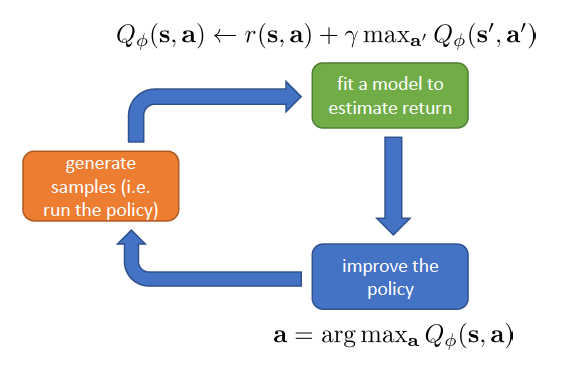
If we don't want to learn a policy, we could learn value funtions.
Summary
We don’t need to learn a policy, instead we’ll use the policy that choose the action to get maximum Q-value at the current state.
For example, offline Q-learning:
online Q-learning:
take an action ai and observe (si,ai,si′,ri)
yi=ri+γmaxa′Qϕ(si′,ai′)
ϕ←ϕ−α∂ϕ∂Qϕ(si,ai)(Qϕ(si,ai)−yi)
This method is not guaranteed to converage.
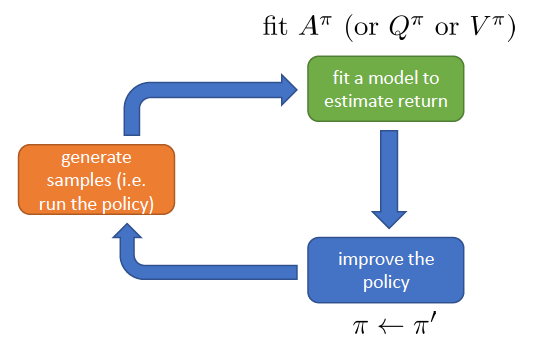
policy iteration algorithm
Since Aπ could denote how much better is at than the average actions accroding to π, atargmaxAπ means we take the best action from st if we follow π
choose the best action from st, the policy will be:
Recall we have Aπ(st,at)≈r(st,at)+Vπ(st+1)−Vπ(st) from actor-critic, now we need to evaluate Vπ(st)
Tabular reinforcement learning
Assume we know the transition probability p(s′∣s,a), and st,at are both discreate. Then we could do tabular reinforcement learning, store Vπ(st) into a table, update Vπ(st) at every one step by:
Vπ(s)←r(s,π(s))+γEs′∼p(s′∣s,π(s))[Vπ(s′)]
In order to simplify the above equation, we could use Q to replace V, so the procedure will be:
construct the q-value table by: Q(s,a)=r(s,a)+γE[V(s′)]
V(s)←maxaQ(s,a)
Notice we would use the q-value to update value function at step2, so just combine them together, we would get rid of value function entirely, now the procedure will be:
construct the q-value table by: Q(s,a)=r(s,a)+γE, E is the expected value of the next time step
set the q-value to be the max
Fitted Q-iteration
When the number of states is large, it’s impossible to construct a table, so we use neural network here.
We would train a neural network that maps state to an estimated reward: V(s)→R, then we will optimize this network by:
L(ϕ)=21∥Vϕ(s)−amaxQπ(s,a)∥2
Note: sometimes the gradient might be too big, so we may change the loss function to Huber loss or use gradient clip.
The training will be:
set yi←maxai(r(si,ai)+γE[Vϕ(si′)])
set ϕ←ϕargmin21∥Vϕ(s)−yi∥2
Notice we still need to know the transition probability to calculate Es′∼p(s′∣s,a) in step1, to fit this, we approxiate E[Vϕ(si′)]≈maxa′Qϕ(si′,ai′)
This q-learning works for off-policy samples, and it has only one network, no need to do policy gradient. But it’s not guaranteed to converage.
The full algorithm is below:
Q Learning
An online q-learning will be:
take an action ai and observe (si,ai,si′,ri)
yi=ri+γmaxa′Qϕ(si′,ai′)
ϕ←ϕ−α∂ϕ∂Qϕ(si,ai)TD error(Qϕ(si,ai)−yi)
Explore and Exploit
If the action we choose at very fisrt is bad, and we only take actions to maximize the Q value, we might stuck in the bad loop.
In order to solve this, we need to do some actions to explore. epsilon-greedy
We take the actions that arg max Q value at the probability of 1−ϵ, that is:
So when the policy is good, we could use smaller ϵ and larger ϵ when the policy is bad.
Usually, starts with large epsilon and gradually decrease. Boltzmann exploration
Select actions in proportion to some positive transformation of Q values, and the most popular one is exp. Using this the best actions would appear at the highest frequency.
π(at∣st)∝exp(Qϕ(st,at))
Implement
Questions
what is dynamic programming here? is it different from DP in code contests?