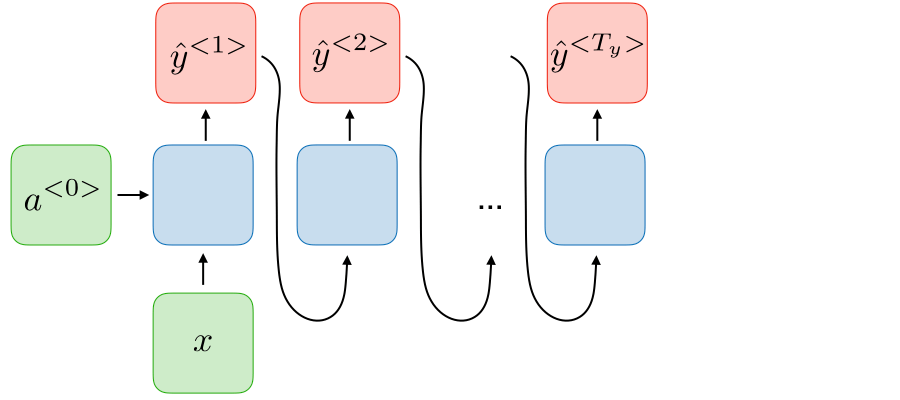
Consider all the samples as one cluster, then split into sub-clusters depending on distances.
Combine
Consider each sample as one cluster, then combine the nearest into one cluster.
K-means
NP-hard problem
Steps:
Select k random nodes as the center of clusters
For the rest of n-k samples, calculate the distance between the sample with the centers
Classify the sample to the nearest cluster
Re-calculate the center of the clusters
Repeat 3-4 until the centers don’t change anymore
How to decide the first centers
The randomly selected nodes as first centers would influence the results of the clusters.
Solutions:
Select the initial centers for multiple times
Use hierarchical clustering to find k clusters, and then use them as the initial centers.
How to choose k
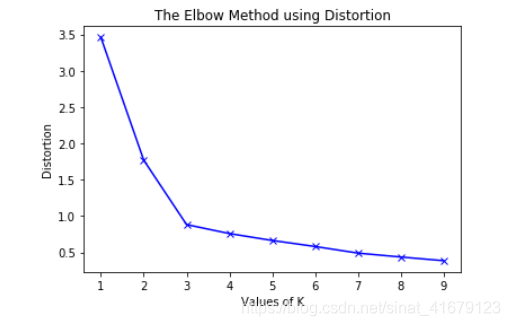
If not decided by business rules, then use elbow rule.
Draw a linear picture between values of k and diameter of clusters:
Elbow Rule
The x is the values of k, and the y is the diameter of the clusters, eg, the sum of the square distance between points in a cluster and the cluster centroid.
Rendle, S. (2010). Factorization machines. 2010 IEEE International Conference on Data Mining (pp. 995–1000).
Summary
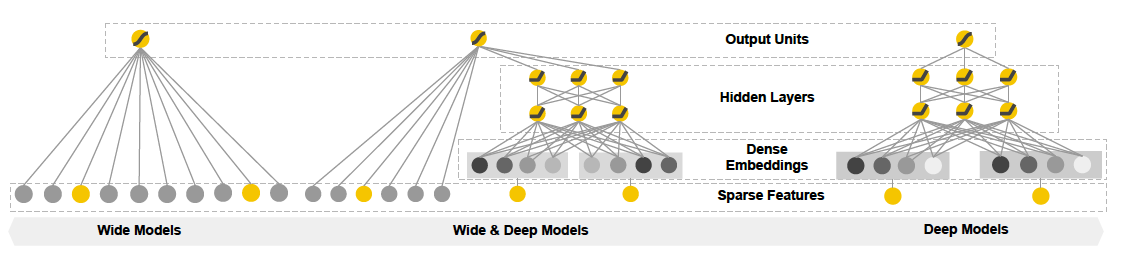
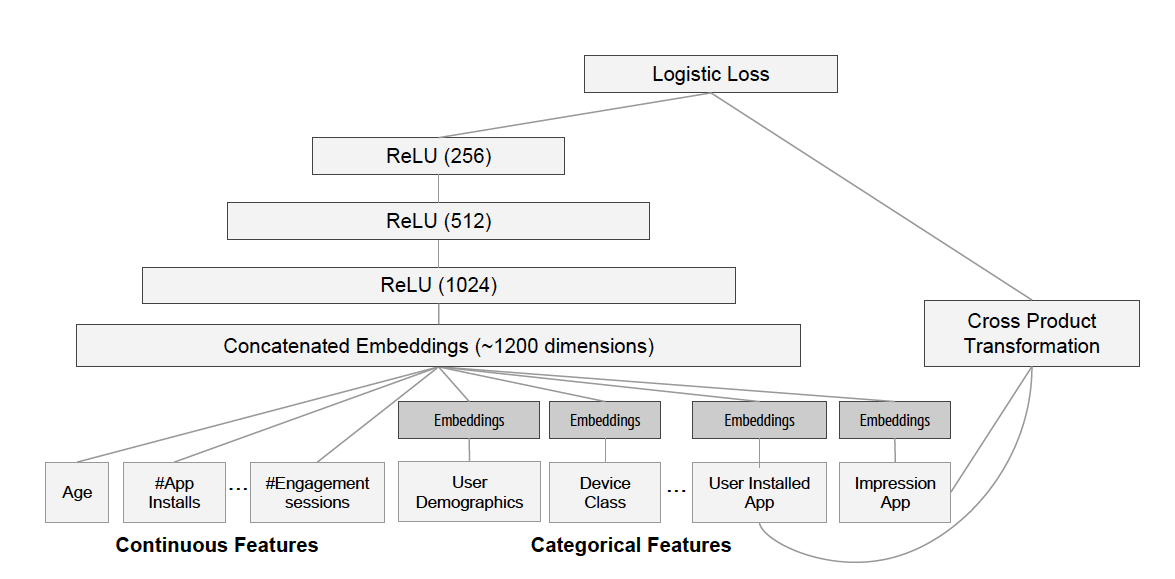
Introduced the crossed feature with low computational complexity to be o(kn), where k is the dimension of latent vector, and n is the dimension of original feature
Suitable for sparse feature. When feature is sparse, could use smaller k to fit.
Details
Assume we have n features in total, if we need to fit the interaction between 2 features (2-degree), then the model will be:
f(x)=w0+i=1∑nwixi+i=1∑nj=i+1∑nwijxixj
Since the number of xixj is 2n(n−1), the computational complexity of this model is o(n2).
Because wij is a symmetric matrix, and accroding to Cholesky decomposition, every symmetric matrix is a product of lower-triangular matrix and its transpose, so we have:
W=VTV
Where V is a vector of K dimension, and could be seen as the latent vector.
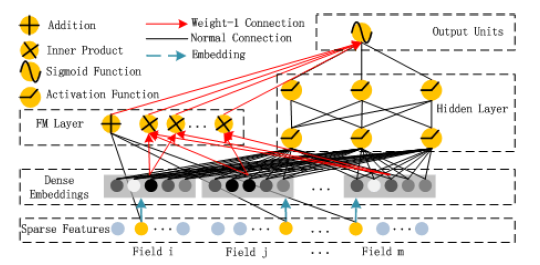
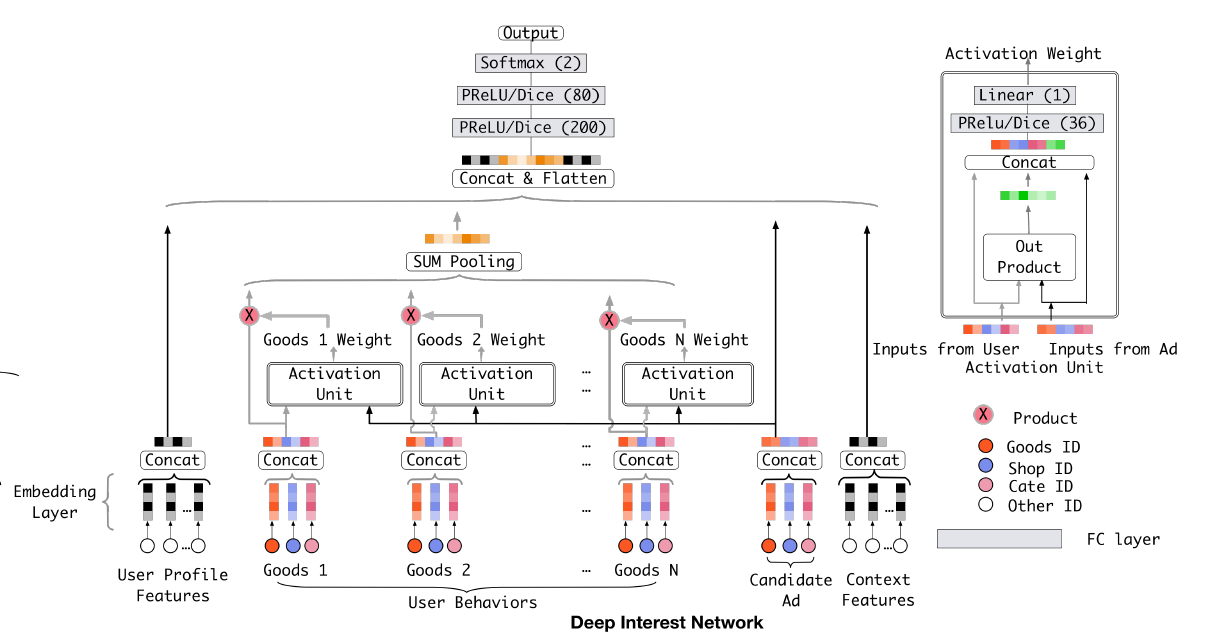
Use attention mechanism where:
Query: target ad
Key: User behavior
Value: User behavior
And use an activation network to replace attention score function.
Details
DIN
TODO
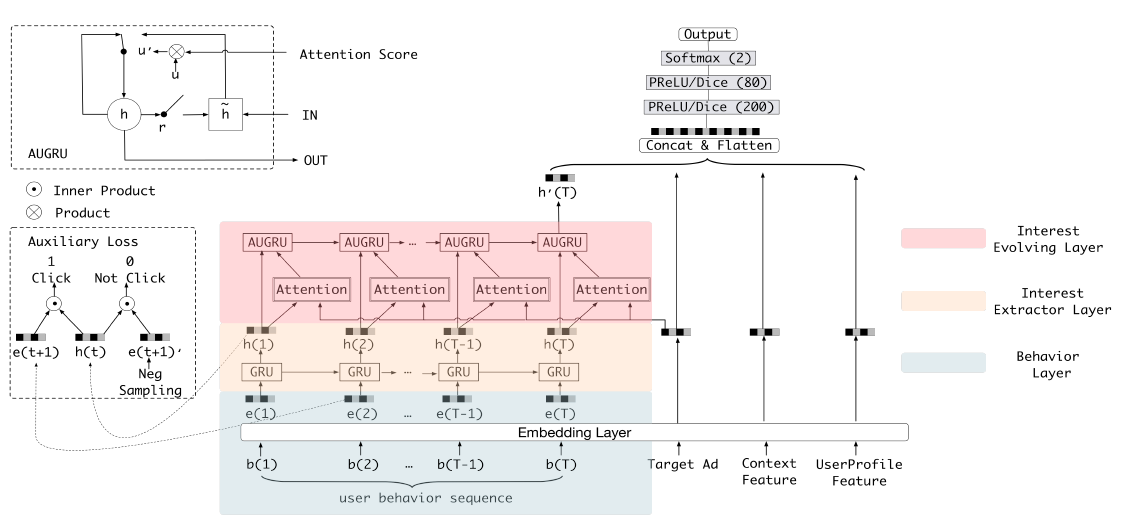
DIEN/Deep Interest Evolution Network for Click-Through Rate Prediction
differentiable so we could use back-propagation to learn parameters and optimize loss function
the function and its derivative should be as simple as possible
speed up the calculation
the derivative should fall in a certain range, not too large, not too small
otherwise it would slow down the training speed (TODO: why, ReLU doesn’t obey this)
*Note: Any differentiable function must be continuous at every point in its domain. The converse does not hold: a continuous function need not be differentiable. Eg: y=∣x∣ is continuous, and differentiable everywhere except x=0.
sigmoid
Logistic
σ(x)=1+e−x1
Property:
σ′(x)=σ(x)∗(1−σ(x))
σ(x)=1−σ(−x)
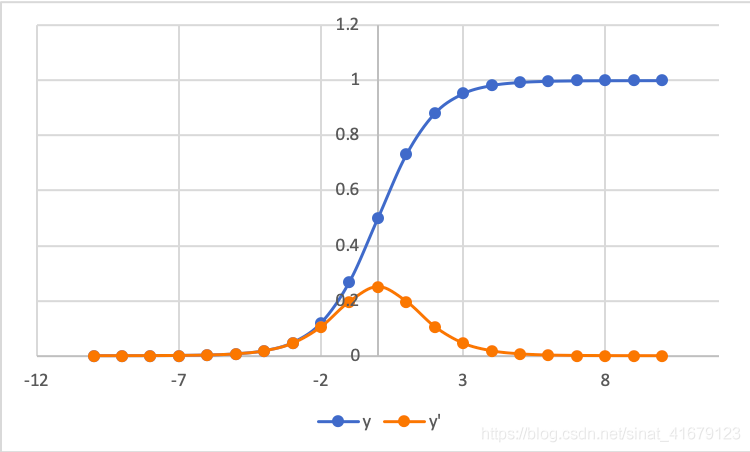
Sigmoid and its derivative
For sigmoid function, when x∈[−3,3], y=σ(x) is nearly linear, and y is either 0 or 1 for x outside this range. We call [−3,3] as a non-saturation regions.
For its first derivative, σ′(x)≈0 when x∈/[−3,3].
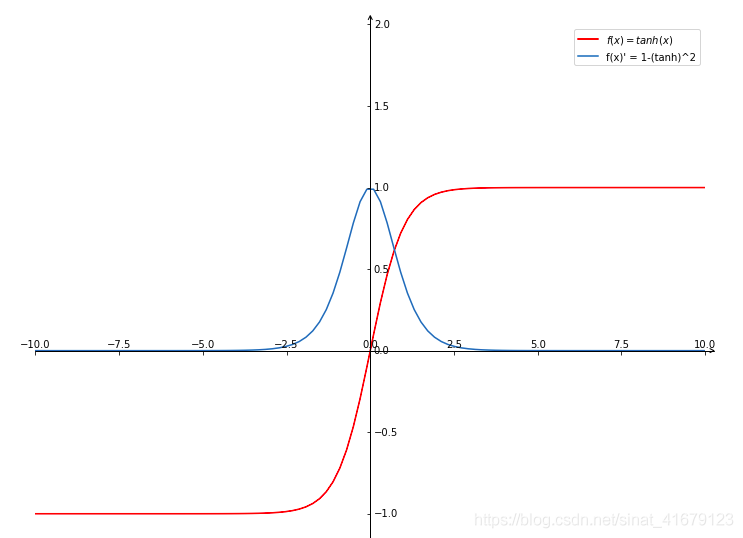
tanh
tanh(x)=ex+e−xex−e−x
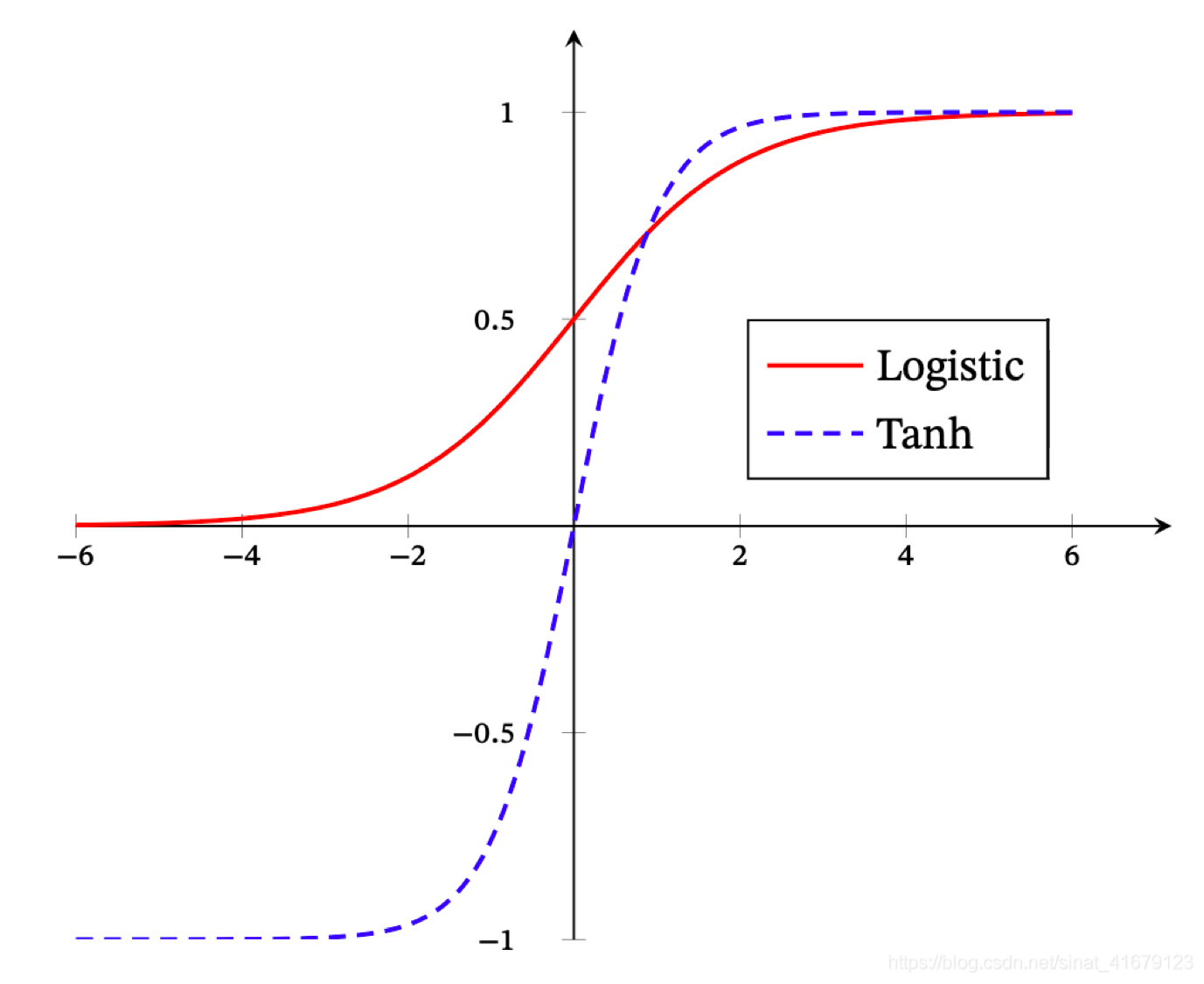
tanh and sigmoid
First derivative: tanh′(x)=1−[tanh(x)]2
tanh and its derivative
@TODO
ReLU/Rectified linear unit
Vanilla ReLU
relu(x)=max(0,x)={x,0x≥0x<0
Advantages
Sparse activation: For example, in a randomly initialized network, only about 50% of hidden units are activated (have a non-zero output).
Better gradient propagation: Fewer vanishing gradient problems compared to sigmoidal activation functions that saturate in both directions.
Efficient computation: Only comparison, addition and multiplication.
Scale-invariant: max(0,ax)=amax(0,x),∀a≥0
Disadvantages
Non-differentiable at zero: however, it is differentiable anywhere else, and the value of the derivative at zero can be arbitrarily chosen to be 0 or 1.
Not zero-centered: neurons at later layers would have a position bias.
Unbounded.
Dying ReLU problem (vanishing gradient problem): When x<0, the derivative of ReLU is 0, meaning the parameter of the neuron won’t udpate by back propagation. And all the neurons that are connected to this neuron won’t update.
Possible reasons
The initialization of parameters
Learning rate is too large. The parameters change too fast from positive to negative.
Comparision between different activation functions
TODO
Activation functions developed like this: sigmoid -> tanh -> ReLU -> ReLU variants -> maxout
Activation Function
Advantage
Disvantage
sigmoid
The range of output is (0,1)
1. First derivative is nearly 0 at saturation region 2. Not zero-centered, the inputs for later neurons are all positive 3. Slow because of exponential calculation
tanh
Zero-centered, the range of output is (−1,1)
1. First derivative is nearly 0 at saturation region 2. Slow because of exponential calculation
ReLU
1. Only 1 saturation region 2. Easy to calculate without exponential
dead ReLU problem
ReLU variants
leaky ReLU, etc. Solved the dead ReLU problem
maxout
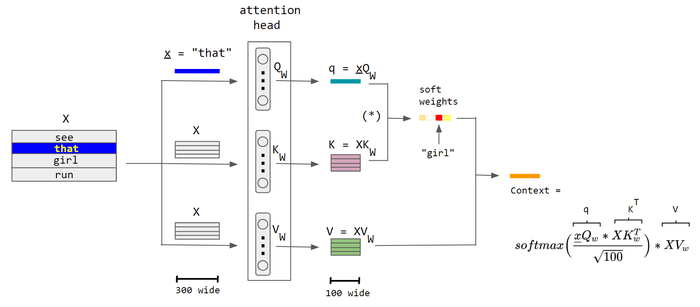
Attention Mechanism
Attention works as a weighted sum/avg, the attention score is the weights of every input.
Let’s say inputs are X, here’s how self KV-attention works:
KV Attention
The output is:
O(X)=i=1∑nαivi
where αi is the attention score of xi, in KV attention, it’s calculated by:
αi=f(K,Q)
Some common ways to calculate attention:
Standard Scaled Dot-Product Attention
Attention(Q,K,V)=softmax(dkQKT)∗V
Multi-Head Attention
MultiHead(Q,K,V)=Concat(head1,head2,...)W
where each head was calculates as:
headi=Attention(Q,K,V)
Positional Embedding
Instead of using LSTM/GRU, use positional embedding to capture the positions, usually appears in transformers.
Suppose we have an input sequence with length L, then the positional embedding will be:
P(k,2i)P(k,2i+1)=sin(n2i/dk)=cos(n2i/dk)
Where:
k is the index of position
d is the dimension of positional embedding
i is used for mapping column indices
n is user-defined number, 10,000 in attention is all you need.
Below is an example:
Example for positional embedding
In transformer, the author added the positional embedding with word embedding, and then feed it into transformer encoder.
How positional embedding works in transformer
Implementation of positional embedding
1 2 3 4 5 6 7 8 9 10 11 12 13 14
import numpy as np import matplotlib.pyplot as plt def getPositionEncoding(seq_len, d, n=10000): P = np.zeros((seq_len, d)) for k in range(seq_len): for i in np.arange(int(d/2)): denominator = np.power(n, 2*i/d) P[k, 2*i] = np.sin(k/denominator) P[k, 2*i+1] = np.cos(k/denominator) return P
# P.shape: seq_len * d P = getPositionEncoding(seq_len=4, d=4, n=100)
Normalization
Note: I call all kinds of feature scalings as normalization.
Why feature scaling?
When model is sensitive to distance. If no scaling, then the model will be heavily impacted by the outliners. Or the model will be impacted by features with large ranges.
If dataset contains features that have different ranges, units of measurement, or orders of magnitude.
Do the normalization on training set, and use the statistics from training set to test set
Max-Min Scaling/unity-based normalization
Scaled features to range from [0, 1].
X′=Xmax−XminX−Xmin
When X=Xmin, then X′=0. On the other hand, when X=Xmax, X′=1. So this range will be [0, 1]
It could also generalize to restrict the range of values in the dataset between any arbitrary points a and b.
X′=a+Xmax−XminX−Xmin∗(b−a)
Log Scaling
Usually used when there are long tail problems.
X′=log(X)
Z-score
X′=std(X)X−mean(X)
After z-score, the distribution of the data would be normal distribution/bell curve.
Property of normal distribution:
μ=0
σ=1
For linear models, because they assume the data distribution is normal, so better do normalization.
Batch Normalization
Why use batch normalization?
Because in deep neural networks, the distribution of data will shift through the layers, which is called internal variance.
So we use BN between layers to mitigate the consequences.
How do we do batch normalizations?
For every mini-batch, calculate the normalization of each feature on every sample. The μ and σ are the mean and the variance of the samples respectively.
To be less restrictive, batch normalization add a scaling factor γ and an offset β, so the result is:
XBNx^=γx^+β=σ(x)x−μ(x)
Limitations
BN calculates based on the batch, so the batch size needs to be big.
Not suitable for sequence models.
Layer Normalization
Similar to BN, but do the normalization based on feature scale. The μ and σ are the mean and variance of the features on one sample respectively.
LN is calculating the normalization of the features, it’s scaling different features.
LN is more common in NLP, transformer uses layer normalization.
Regularization
Dropout
Dropout is a layer, it can be applied before input layer or hidden layers.
For input layer, the dropout rate is usually 0.2, which means for every input neuron, there’s 80% chance they will be used.
For hidden layer, the dropout rate is usually 0.5.
Why do we have thus problems?
Back propagation computes the gradient by chain rule. From the back propagation formula, we could see if the number of hidden layers is large, then the result would involve many intermediate gradients. And if the intermediate gradients are below 1, then the products of them would decrease rapidly, thus the gradient would vanish. On the other hand, if the gradients are all above 1, then the product would increase rapidly, so the final gradient would explode.
How to deal with gradient exploding?
To deal with gradient exploding, we can use a gradient clip method. When the gradient is above the threshold, then:
g=∣∣g∣∣∣∣Threshold∣∣∗g
How to deal with gradient vanishing?
Model architecture: use LSTM, GRU.
Residual: Add residual into the network
Batch Normalization: TODO
Activation function: use ReLU instead of sigmoid
Convolutional Neural Network (CNN)
@TODO
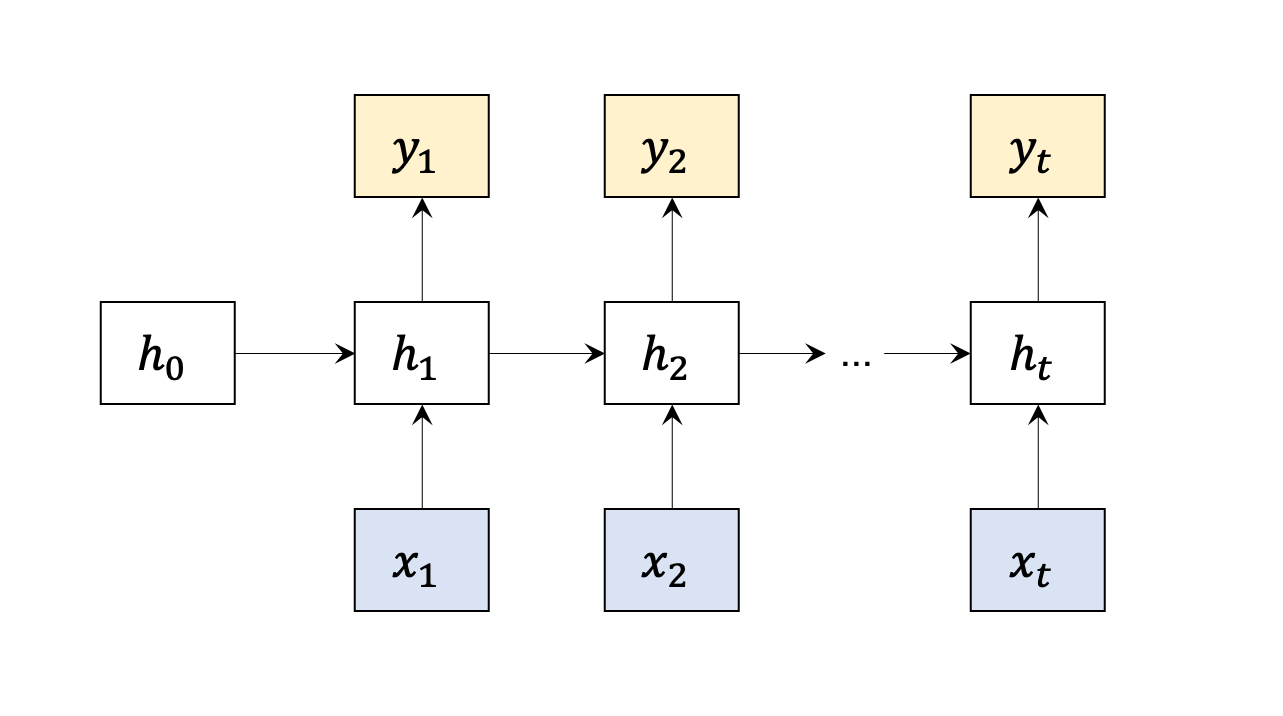
Recurrent Neural Network (RNN)
Sometimes the output of the neural network is not only related to input, but also related to current state (output from last time period)
Vanilla RNN
vanilla rnn
Forward:
{htyt=fh(WxX+Whht−1+bx)=fy(Wyht+by)
Note: Wx,Wh,Wy doesn’t change accroding to t, that’s called weight shareing.
RNN & Gradient Vanishing
For rnn, the gradient vanishing problem is even more severe, because usually the length of sequence is large.
Long Short Term Memory/LSTM
In vanilla RNN, ht is changing all the time, and it’s only based on the previous state, like a short memory. So here in LSTM, we introduce a cell ct to use longer memories (long short memory).
here we use σ because σ has a value of [0,1], which is “gate”.
4. The number of trainable parameters is related to input dimension and hidden layers, which is: (input_dim + hidden_unit + 1) * hidden_unit * 4 Proof: Trainable parameters come from 4 parts: 3 gates and the neural network. Since the inputs of the networks are concatenation of xt and ht, the dimension of the concatenated vector is 1 x (input_dim + hidden_unit). And we have 1 dimension for b, so for one part, the dimension is (input_dim + hidden_unit + 1) x hidden_unit, times 4 we get the final answer.
Gated Recurrent Unit/GRU
In LSTM, we have redundant gates ft and it. So instead of using 3 gates, we only use 2 gates in GRU, reset gate rt and update gate ut.
Sampling without replacement, in which a subset of the observations are selected randomly, and once an observation is selected it cannot be selected again. Sampling with replacement, in which a subset of observations are selected randomly, and an observation may be selected more than once.
If we have m samples, and we do this sampling for m times, after choosing one item, we put it back. Then the sample size would be 63.2% of the original set.
Math details:
The probability of not being chosen is 1−m1, so the probability of not chosen after m times is (1−m1)m, if m is large enough, then we have:
m→∞lim(1−m1)m=e1≈0.368
Selecting a stratified sample, in which a subset of observations are selected randomly from each group of the observations defined by the value of a stratifying variable, and once an observation is selected it cannot be selected again.
Upsampling/Oversampling
SMOTE (Synthetic Minority Oversampling Technique)
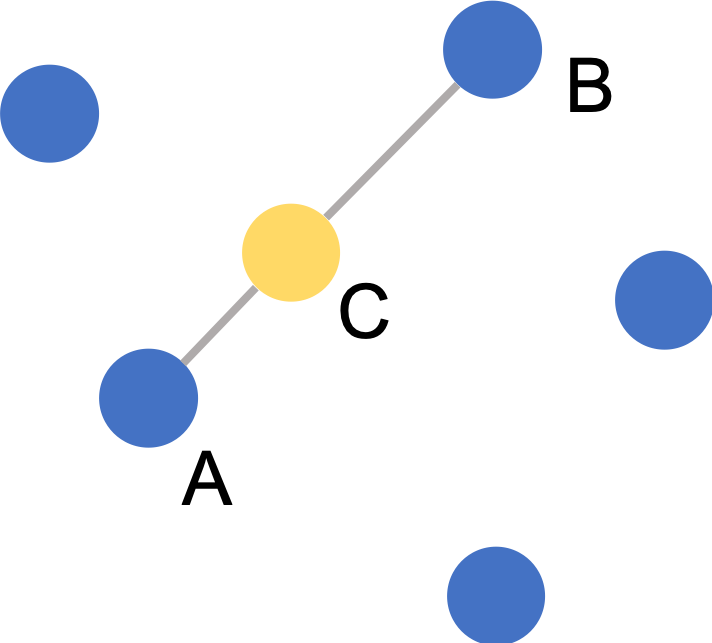
Synthesize samples for the minority class.
Assume we need to oversample by N, then the steps are:
Select 1 minority sample and find its knn.
Randomly choose N nodes from k neighbors.
Interpolate the new synthetic sample.
Repeat 1-3 for all samples in minority class.
Interpolate as follows:
SMOTE
Node C is synthesized based on the difference between node A and node B. The synthetic nodes are always in the same direction of its base nodes.
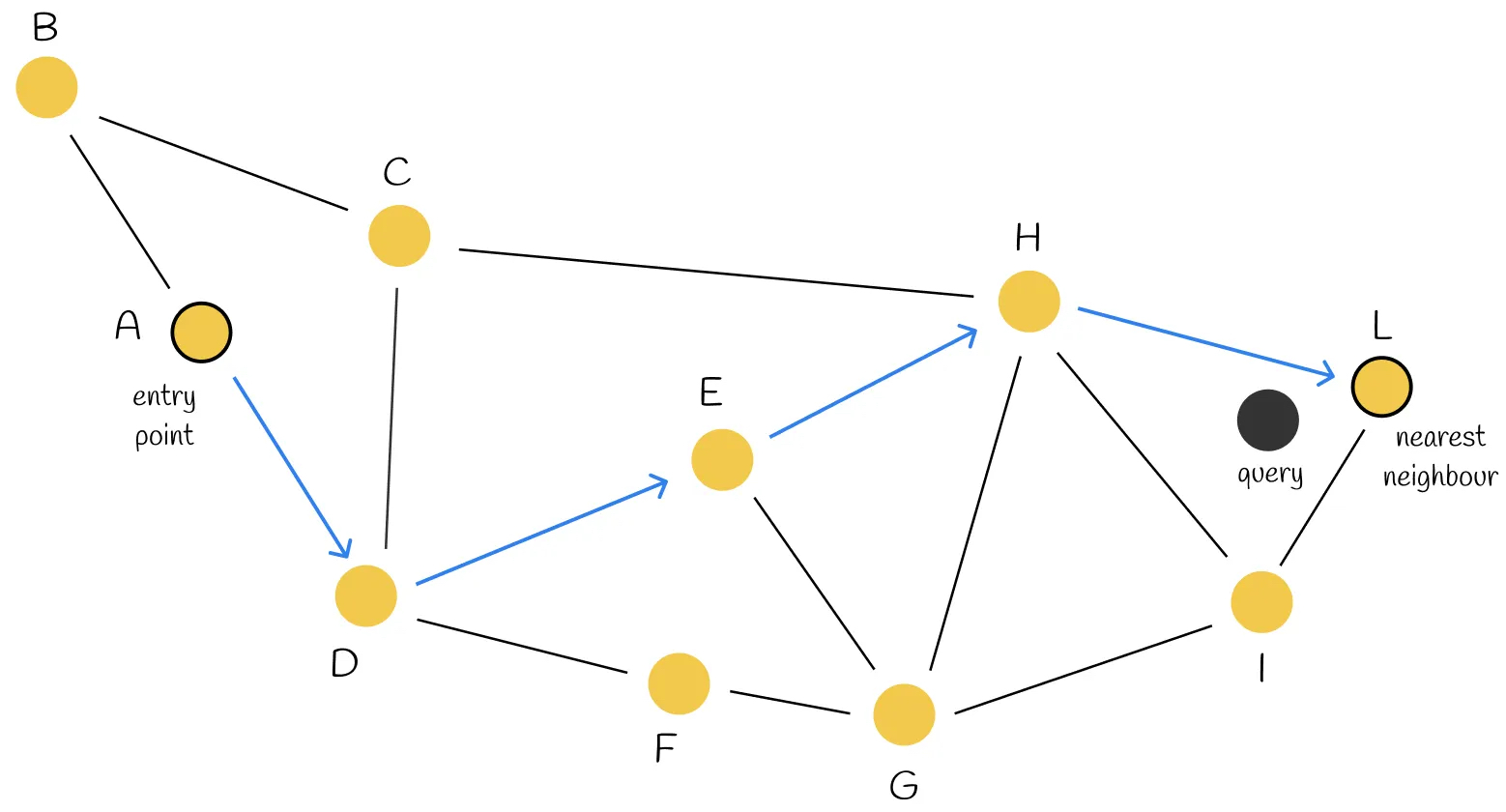
Intrinsic search: start with A, and then iterate all its neighbors to find the nearest one to query. Then move to the nearest neighbor. Repeat this process until there is no neighbor nodes that are closer than the current node. The current node is returned as the result.
Questions:
What if there’s some nodes that have no neighbors?
If we want to find the nearest 2 nodes for query, and these 2 nodes are not connected, then we need to run the whole graph twice, which costs lots of resources.
How to build the graph? Does node G really need those neighbors?
Answers:
When building graph, make sure that every node has at least 1 neighbor.
When building graph, make sure that if 2 nodes are close enough, they must have an edge.
Reduce the number of neighbor as much as possible.
How to build a graph, see NSW method.
NSW
In order to build a graph, firstly shuffle data points and then insert the nodes one by one.
When inserting a new node, link it with nearest M nodes.
Long-range edges will likely occur at the beginning phase of the graph construction.
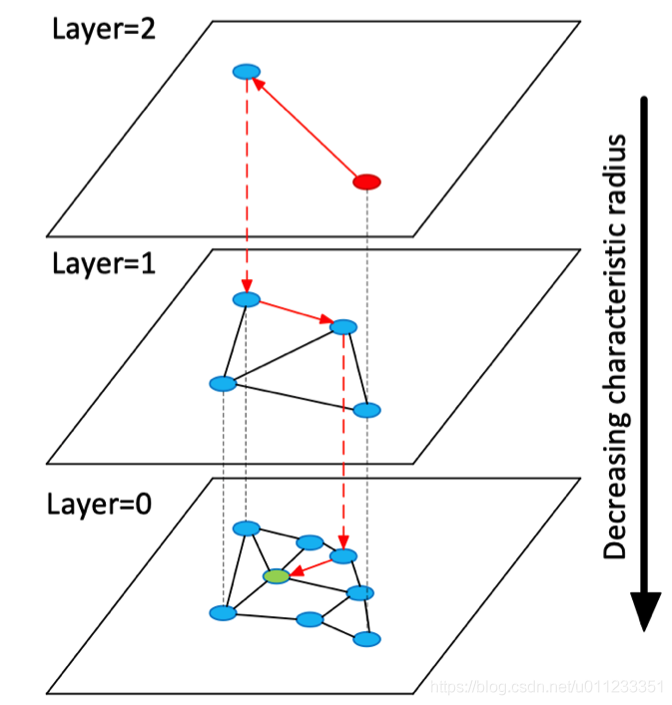
HNSW
HNSW Search
Build Graph: Use a parameter to decide whether this node needs to be inserted into certain layer. And the node is inserted into its insertion layer and every layer below it.
Search Graph: Start with top layer, find the nearest node greedily, and then go to lower layer. Repeat until the 0 layer.
K-Fold Cross Validation
@TODO
Normalization
The goal of normalization is: transform features to be on a same scale.
For batch Normalization and layer normalization, they are used in deep learning models, see details here.
Key: Find k nearest neighbors of the current node, and use them to decide its class. So:
The definition of “near”?
How to decide which k should we use?
After we have k neighbors, what rule should we follow to decide the current node’s class?
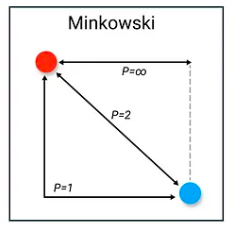
Distance Metric
The Minkowski distance or Lp distance is a metric in a normed vector space which can be considered as a generalization of other common distance metrics.
Information gain is based on entropy. Since entropy is the measure of the amount of information that data carries, information gain is the difference between two amounts of information. One is before using the current feature to split the data, one is after using the current feature.
When using information gain to choose the feature, we would naturally choose the feature with more values. So we introduce information gain ratio to solve this problem.
gR(D,A)=HA(D)g(D,A)
Where HA(D) is the entropy of feature A in dataset D. It’s similar to the way we calculate the entropy of the whole dataset, this time we only use data that has feature A.
HA(D)=−i=1∑NADDilogDDi
Where D is the number of samples in the dataset.
Build the Tree
ID3 algorithm
Use information gain to choose the feature when spliting data
How to apply tree models to classification/regression problems?
TODO
Ensemble Learning
Ensemble methods use multiple algorithms to obtain better predictive performance than could be obtained from any of the constituent learning algorithms alone.
Bagging/Bootstrap aggregating
What is bootstrap dataset? A bootstrapped set is created by selecting from original training data set with replacement. Thus, a bootstrap set may contain a given example zero, one, or multiple times.
To get a bootstrap dataset, we do a sampling with replacement, so an observation may be selected more than once.
What is aggregation? Inference is done by voting of predictions of ensemble members.
For classification problems, use the voting results. If 2 labels tied, consider adding confidence.
For regression problems, use average, eg simple average, or weighted average with weights of base models as the average weights.
Random Forest/RF: an implementation of bagging and decision tree
Use decision tree as the base model, and add a randomness for feature selection, which is choose n features from current m candidates, and select optimal feature based on these n features.
n=m: traditional decision tree
n=1: randomly select 1 feature to split the data
n=log2m: recommended choice
Overall, random tree has 2 randomness.
Randomness in sample selection: because of bootstrap sampling, the dataset is sampled randomly.
Randomness in feature selection: the optimal feature is not chosen from all the features, instead it’s chosen based on randomly selected feature candidates.
Advantage
Disadvantage
Boosting
Core idea: learn a bad base model first, then keep boosting the performance until reaching a perfect standard.
Adaboost/Adaptive Boosting
Steps:
Calculate error rate em: the sum of classifier weights that give wrong predictions.
Calculate new weight αm: αm=21∗lnem1−em. Note here αm is inversely proportional to em.
Where y−fm(x) is a constant that denotes the difference between the true value and predicted value by last round classifier, which is the residual r, so now we have:
Which means every iteration, we train a tree to fit the residual.
But boosting tree is only valid when using MSE as the loss function, so we have GBDT instead.
GBDT/Gradient Boosting Decision Tree
Use negative gradient to approximate the residual, that is:
rmi=−[∂f(xi)∂L(yi,f(xi))]f(x)=fm−1(x)
For MSE, this is the standard residual, for other loss function, this is an approximate for residuals.
Traditional Implementation
Iterate all the feature candidates, split data based on current feature, then calculate fitted residuals based on all data, ri=−[∂fm−1(xi)∂L(yi,f(xi))]. Then use loss function to calculate loss, and choose the feature with minimum loss as the feature to split the data.
So the time complexity of traditional implementation is proportional to the number of feature times the number of samples.
Regularization
Shrinkage/Learning Rate
fm+1(x)=fm(x)+ν⋅αmT(x,Θ)
where 0<ν<1
Using small learning rates (such as ν<0.1) yields dramatic improvements in models’ generalization ability over gradient boosting without shrinking (ν=1). However, it comes at the price of increasing computational time both during training and querying: lower learning rate requires more iterations.
Stochastic Gradient Boosting Tree/SGBT
The base model should be trained on bootstraped datasets. Use f to denote the size of training set.
f=1: same as gradient boosting
0.5≤f≤0.8: recommended interval
f=0.5: most common choice
Number of Observations in Leaves
Limiting the minimum number of observations in trees’ terminal nodes. Penalize Complexity of Tree L2 penality on the leaf values.
XGBoost/eXtreme Gradient Boosting
Xgboost is modified based on gbdt, where it added regularization and use a second order taylor series to get a more precise loss function.
Calculate the derivative of loss function of w, then we have:
∂w∂L=∑g+(∑h+λ)w
Let derivative = 0, then we have optimal w:
w∗=−∑h+λ∑g
Then the minimum loss (with constants) is:
Loss(y,y^)=−21j=1∑T[∑h+λ(∑g)2]+γ∣T∣
From the loss function formula we know the loss is related to the structure of the tree (T in the equation). So in order to find the minimum loss, we need to iterate all different structured trees, which is too time-consuming.
Consider a heuristic method, start with a single node, and then find the next feature to split the data. The criteria for selecting feature is, after spliting by this feature, the loss would decrease.
Loss reduction:
Loss Reduction=Lno split−(Lleft nodes after spliting+Lright nodes after spliting)=−21[∑hn+λ(∑gn)2−∑hl+λ(∑gl)2−∑hr+λ(∑gr)2]+γ(1−1−1)=21[∑hl+λ(∑gl)2+∑hr+λ(∑gr)2−∑hn+λ(∑gn)2]−γ
Tree generation based on pre-sorted features
If loss reduction > 0, then this feature should split the data, else we should prune. So everytime we find the maximum loss reduction to split the data.
To speed up the spliting, we calculate the feature reduction first:
Loss Reduction=Lno split−(Lleft nodes after spliting+Lright nodes after spliting)
and then sort them from largest to smallest.
Pros: fast speed, could run in parallel.
Cons:
Need to iterate all the data to calculate loss reduction
Need to store the sorted results
Note: Even xgb could run in parallel, it’s parallel in feature level, not in data level.
In information theory, entropy is the amount of uncertainty, assume the probability distribution of a single discreate random variable x is P(x), then the entropy of x is:
H(x)=−x∑P(x)logP(x)
Note: Entropy cares only the probability distribution of a variable, it has nothing to do with the value of the variable.
Joint Entropy
For 2 discreate random variables X and Y, assume the joint probability distribution is P(x,y), then the joint entropy is:
H(X,Y)=−x,y∑P(x,y)logP(x,y)
Properity
Non-negativity
Greater than individual entropies: H(x,y)≥max[H(x),H(y)]
Less than the sum of individual entropies: H(x,y)≤H(x)+H(y)
Conditional Entropy
The conditional entropy quantifies the amount of information needed to describe the outcome of a random variable Y given that the value of another random variable X is known.
Joint entropy is 2 random variables over 1 probability distribution
Cross entropy is 1 random variable over 2 different probability distributions p, q
Cross entropy is widely used as a loss function in ML because of its relationship with KL divergence.
KL Divergence/Relative Entropy
KL divergence is the measure of how one probability distribution P is different from a second, reference probability distribution Q, or the loss you would get when you want to use p to approxmate q.
Since KL divergence is the measure of distance between 2 probability distributions, it’s range is [0,+inf). KL(p∣∣q)=0 if and only if p=q.
KL(p∣∣q) is converx in the pair of probability measures p,q.
Mutual Information/MI/Information Gain
Mutual information is a measure of the mutual independence between two variables. Eg: X is the result of a dice, and Y is whether X is odd or even. So from Y we could know something about X.
It’s also known as the information gain, which is defined as:
Info Gain(Y,X)=H(Y)−H(Y∣X)
Performance Evaluation
Confusion Matrix
ground truth / predictions
positive
negative
positive
TP(true positive)
FN(false negative)
negative
FP(false positive)
TN(true negative)
Precision
Precision is the fraction of relevant instances among the retrieved instances, which is:
Precision=TP+FPTP
Recall
Recall is the fraction of relevant instances that were retrieved.
Recall=TP+FNTP
Accuracy
Accuracy is how close a given set of observations are to their true value, it treats every class equally.
Acc=TP+TN+FP+FNTP+TN
F1
F1 is the harmonic mean of precision and recall.
F1=2∗Precision+RecallPrecision∗Recall
Fβ
F1 is the special condition of Fβ, the higher β is, the more recall is important over precision.
Fβ=(1+β2)β2∗Precision+RecallPrecision∗Recall
For F-score, it’s calculated based on predicted classes, instead of probabilities.
Use it for classification problems.
Support
TODO
ROC/AUC
A ROC space is defined by FPR(false positive rate) and TPR(true positive rate) as x and y axes, respectively, which depicts relative trade-offs between true positive (benefits) and false positive (costs).
FPR: defines how many incorrect positive results occur among all negative samples available during the test. Or how many negative samples that are higher than the gate are in the all negative samples.
FPR=FP+TNFP
TPR: defines how many correct positive results occur among all positive samples available during the test. Or how many positive samples that are higher than the gate are in the all positive samples.
TPR=TP+FNTP
How to draw ROC curve?
Use probability from the model to rank from large to small, then use the maximum prob as the gate, all samples above the gate are positive, others are negative. Change the gate and calculate the FPR(x) & TPR(y), then draw the line.
AUC is the ability of model to rank a positive sample over a negative sample
AUC
Special positions
(0,0) means classify all the samples to negative, so the FPR=0 and TPR=0
(1,1) means classify all the samples to positive.
xy=FPR=FP+TNFP=# of Negative+0# of Negative=1=TPR=TP+FNTP=# of Positive+0# of Positive=1
Use the sum of many discreate trapezoidals’ areas to approximate AUC, assume we have N samples, then AUC is:
AUC=21i=1∑N−1(yi+yi+1)(xi+1−xi)
Use it for ranking problems
Advantage:
Don’t need to decide a gate value for positive and negative samples.
Not sensitive to positive and negative samples, only care about the ranking.
Disadvantage:
Ignore model’s ability to fit the actual probability. For example, if the model give all positive samples prob as 0.51, and all negative samples as 0.49, auc is 1, but the model is underfitted because of the cross entrophy loss is huge.
Not a good indicator for precision and recall. Sometimes we care only precision or recall.
Don’t care the ranking between positive samples and negative samples.
gAUC/group AUC
@TODO
prAUC
NDCG
Loss Function
Suitable for Classifications
Cross Entropy Loss
Cross entropy is use the estimated data distribution p(x) to approximate the true data distribution q(x), that is: H(p,q)=−∑xp(x)logq(x)
So accroding to this, the cross entropy loss function is:
L(y,y^)=−yTlogy^
Hinge Loss
TODO
Suitable for Regressions
Mean Square Error/MSE/L2
L(y,y^)=n1∗i=1∑n(yi−yi^)2
Mean Absolute Mean/MAE/L1
L(y,y^)=n1∗i=1∑n∣yi−yi^∣
Huber Loss
Huber Loss
Huber loss (green) and squared error loss (blue)
Huber loss is a combination of L1 loss and L2 loss.
Advantage: Optimize L1 & L2 loss’s disadvantages. (When the loss is near 0, use L2 loss. When it’s away from 0, use L1 loss.)
Disadvantage: need to tune δ.
Suitable for Classification + Regression
0-1 Loss
l(y,y^)={1,0,ify=y^ify=y^
Advantage: very straightforward
Disadvantage: discreate; derivative equals to 0, thus hard to optimize
Optimization Algorithms
Gradient Descent & its twists
Steps:
Determine the learning rate.
Initialize the parameters.
Choose samples for calculating the gradient of the loss functions.
Update the parameters.
Note: GD could gurantee the global optimal for convex functions, and local optimal for non-convex functions.
Convex Function
Batch Gradient Descent
Calculate the gradient on all the data, then update the parameters.
Stochastic Gradient Descent/SGD
Calculate the gradient based on 1 single sample, then update the parameters.
Advantage:
Fast, could be used for online learning
Loss function might fluctuate
Glocal optimal not guranteed (could be solved by decreasing learning rate with an appropriate rate)
Mini-batch Gradient Descent
Calculate the gradient on all the data from the batch, then update the parameters.
Usually we use [50,256] as the range for batch size, since mini-batch is very common, in most cases, the sgd in python libraries is actually mini-batch.
w:=w−α∇J(θ)=w−nαi∑n∇J(θ)
where: α is the learning rate, and the batch size is n
Note:
It needs to tune alpha manually.
Global optimal not guranteed.
If the data is sparse, we might want to update the weights more for those frequent features, and less for those less frequent features.
This section is based on this paper: A Maximum Entropy Approach to Natural Language Processing
The principle of maximum entropy is that the best model has the maximum conditional entropy. (Entropy stands for the amount of uncertainty, the more entropy is, the more information the model contains)
Here’s a constrain for maximum entropy model, the statistical distribution of the sample (namely, p~(x,y)) should be inherent to the distribution of the model (namely, p(y∣x)), that means the expection of the model should be inherent to the expection of the samples, that is:
x,y∑P~(x,y)f(x,y)=x,y∑P~(x)P(y∣x)f(x,y)
where:
P~(x,y),P~(x) are the probability for (x,y) and xin sample
p(y∣x) is the model
f(x,y) is a feature function where
f(x,y)={1,0(x,y) exists in samplesotherwise
Objective
Maximize the conditional entropy, that is to maximize H(Y∣X)=−∑(x,y)P~(x)P(y∣x)logP(y∣x)
Parameters Estimation
Optimize the objective under the constrains, we have:
It’s very similar to LR, the only difference lies in the number of classes. In LR there’re only 2 classes while in MEM there’re multiple classes.
Maximum Likelihood Estimator
TODO
Support Vector Machine/SVM
The idea behind svm is to find a boundary between the postivie samples and negative samples, and it tries to find the boundary that has the largest distance to samples.
Linear data, hard-margin
When we could find the boundary, we have a hard-mirgin (data is linearly seperatable)
Find a hyperplane that the minimum distance between any points to the hypterplane is maximum, that is:
maxs.t.dmindx≥dmin
Note: Distance between a point (x,y) to a plane y = wx + b is: d=∣w∣∣wx+b∣
use xmin to denote the point that has the minimum distance, then we have:
Since w∗xmin+b is a constant, we use 1 to replace it. And we times ∣w∣ at both sides of the formula at the constrain, now we have:
maxs.t.∣w∣1∣wxi+b∣≥1,∀xi∈X
Use minimize instead of maximize, we have:
max∣w∣1⇔min∣w∣⇔min21w2
To get rid of the abs in constrain, we multiply true label yi at the constrain, now we have:
mins.t.21w2yi(wxi+b)≥1,∀xi∈X
This is a convex optimization problem, use lagrange multipliers. The lagarangian function would be:
L(w,b,α)=21w2−i∑Nαi[yi(wxi+b)−1]
Then we solve the maximium of w,b, then the minimum of α.
Note: the max-margin hyperplane is completely determined by those xi that lie nearest to it. These xi are called support vectors.
Linear data, soft-margin
When we couldn’t find the boundary, we have soft-margin (data is linear)
When we have some outliners in the dataset, after eliminating these outliners, we could still find the boundary, then it’s a soft-mirgin svm.
To achieve this, we modify the constrains, add some slack, that is: yi(wxi+b)≥1−ζ. At the same time, this slack variable shouldn’t be too large, so the objective function would be:
mins.t.21w2+Ci∑Nζiyi(wxi+b)≥1−ζi
In other way, it would be interpreted that SVM uses hinge loss here.
[@TODO]
Non-linear data
When the data is not linear, we could project the data into another feature space, by using non-linear kernel function to replace every dot product in the low dimension space.
Use ϕ(x):X→H as the projection function, to map x from low dimension space X to high dimension space H, the kernel function is defined as below:
K(x,z)=ϕ(x)⋅ϕ(z)
where x and z are two variables in the low dimension space.