Unsupervised machine learning models
Hierarchical Clustering
Split
Consider all the samples as one cluster, then split into sub-clusters depending on distances.
Combine
Consider each sample as one cluster, then combine the nearest into one cluster.
K-means
NP-hard problem
Steps:
- Select
krandom nodes as the center of clusters - For the rest of
n-ksamples, calculate the distance between the sample with the centers - Classify the sample to the nearest cluster
- Re-calculate the center of the clusters
- Repeat 3-4 until the centers don’t change anymore
How to decide the first centers
The randomly selected nodes as first centers would influence the results of the clusters.
Solutions:
- Select the initial centers for multiple times
- Use hierarchical clustering to find
kclusters, and then use them as the initial centers.
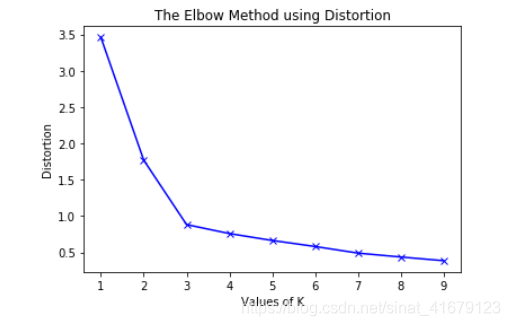
How to choose k
If not decided by business rules, then use elbow rule.
Draw a linear picture between values of k and diameter of clusters:
 |
|---|
| Elbow Rule |
The x is the values of k, and the y is the diameter of the clusters, eg, the sum of the square distance between points in a cluster and the cluster centroid.
From the picture above, the best value of k is 3.
Other Improments for K-Means
Sensitive to Initial Values
k-means++:
Sensitive to Noise and Outliners