Fundamental Models in CTR & Recommender System
FM/Factorization Machines
Rendle, S. (2010). Factorization machines. 2010 IEEE International Conference on Data Mining (pp. 995–1000).
Summary
- Introduced the crossed feature with low computational complexity to be , where
kis the dimension of latent vector, andnis the dimension of original feature - Suitable for sparse feature. When feature is sparse, could use smaller
kto fit.
Details
Assume we have n features in total, if we need to fit the interaction between 2 features (2-degree), then the model will be:
Since the number of is , the computational complexity of this model is .
Because is a symmetric matrix, and accroding to Cholesky decomposition, every symmetric matrix is a product of lower-triangular matrix and its transpose, so we have:
Where is a vector of K dimension, and could be seen as the latent vector.
Now for the model, we have:
And the computational complexity is .
For , we could decompose it by:
So now the model is:
And the computational complexity is
Wide & Deep
https://dl.acm.org/doi/10.1145/2988450.2988454
Summary
Use wide part to fit crossed features, and use deep part to fit embeddings for categorical features.
Details
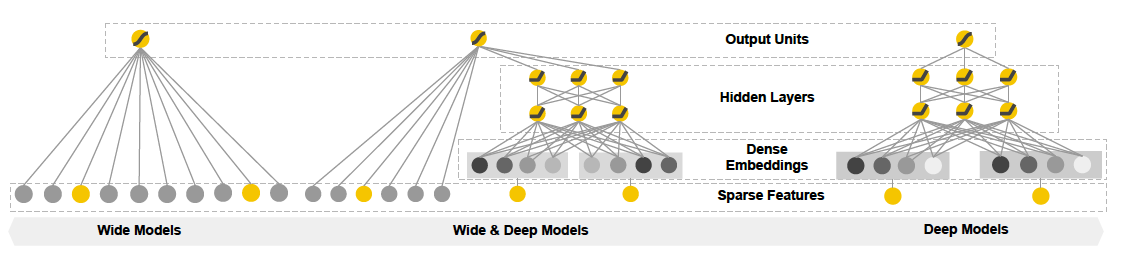 |
|---|
| Wide & Deep |
wide: lr + 2-degree crossed feature,
deep: dnn,
final:
It’s used for app recommendation, so a more business graph is as below:
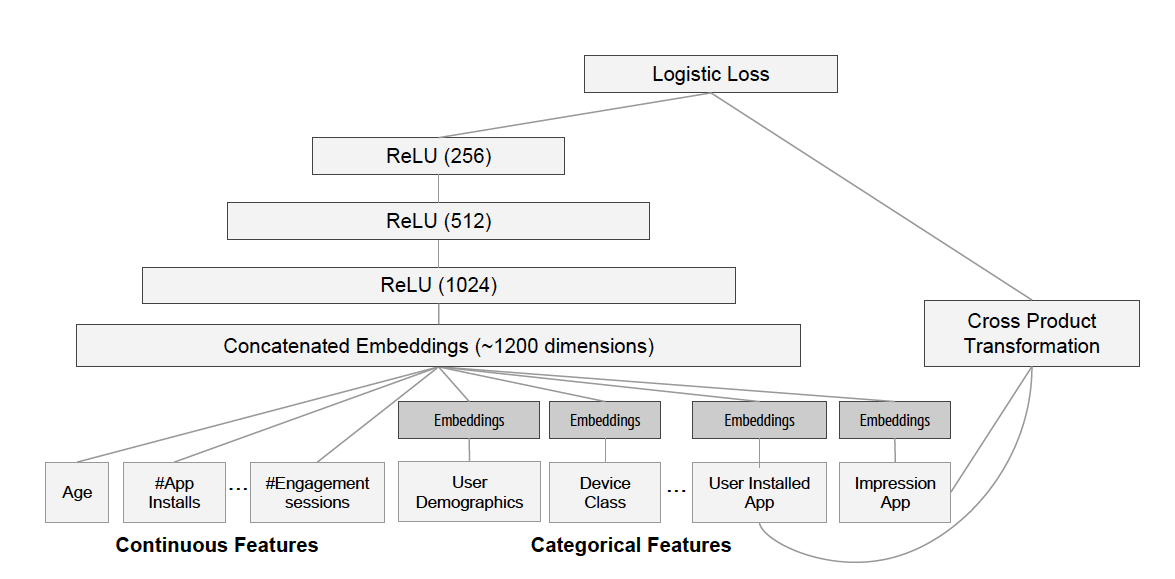 |
|---|
| Wide & Deep for app recommendation |
Here the auther only used user installed app and impression app for crossed features.
what is ReLU(1024)?
Note here, it still requires to choose features for cross features by human, which is diffcult if the number of features is large.
DeepFM
https://arxiv.org/abs/1703.04247
Summary
Use FM to replace wide part in wide & deep, and use embedding for both wide and deep parts.
Details
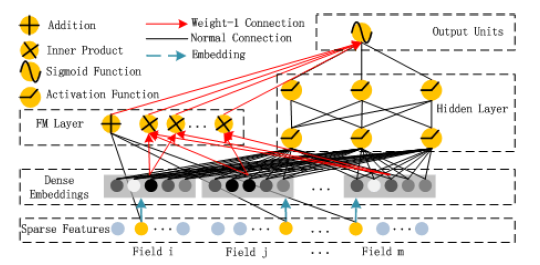 |
|---|
| DeepFM |
Use latent vector from FM as the embedding, to be the input for both deep and wide parts.
DIN/Deep Interest Network for Click-Through Rate Prediction
Summary
Use attention mechanism where:
Query: target ad
Key: User behavior
Value: User behavior
And use an activation network to replace attention score function.
Details
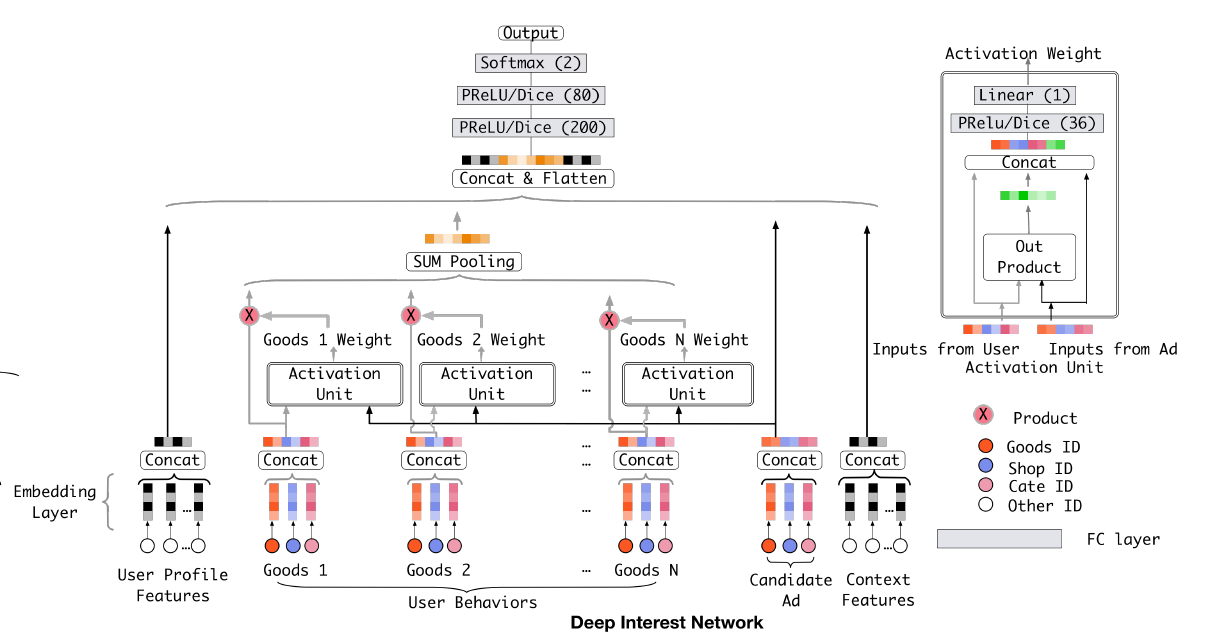 |
|---|
| DIN |
TODO
DIEN/Deep Interest Evolution Network for Click-Through Rate Prediction
Summary
Use GRU to fit user historical behaviour.
Details
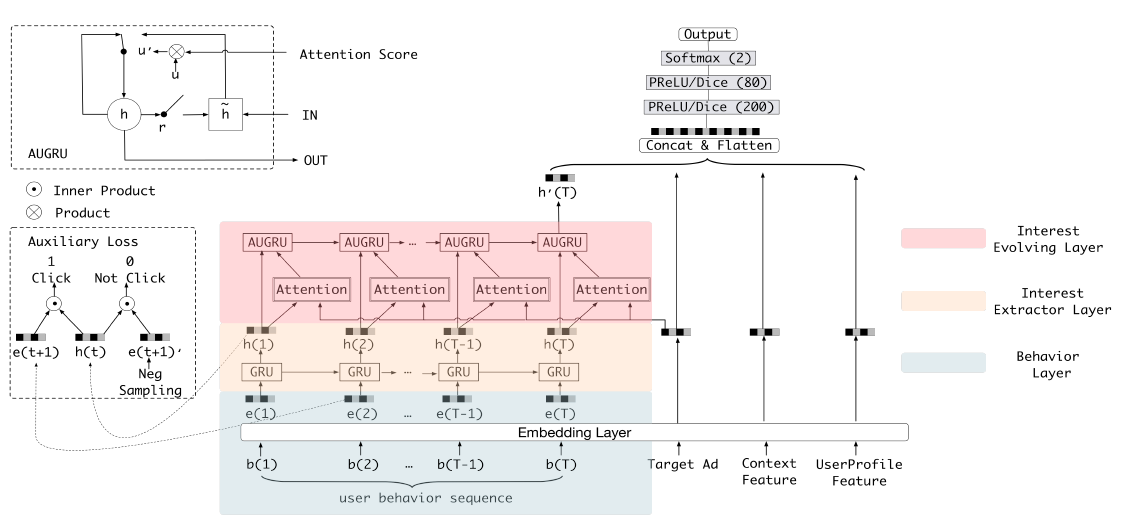 |
|---|
| DIEN |
TODO