Multilayer perceptron (MLP)/ artificial neural network (ANN) / deep neural network (DNN) / feedforward neural network (FNN)
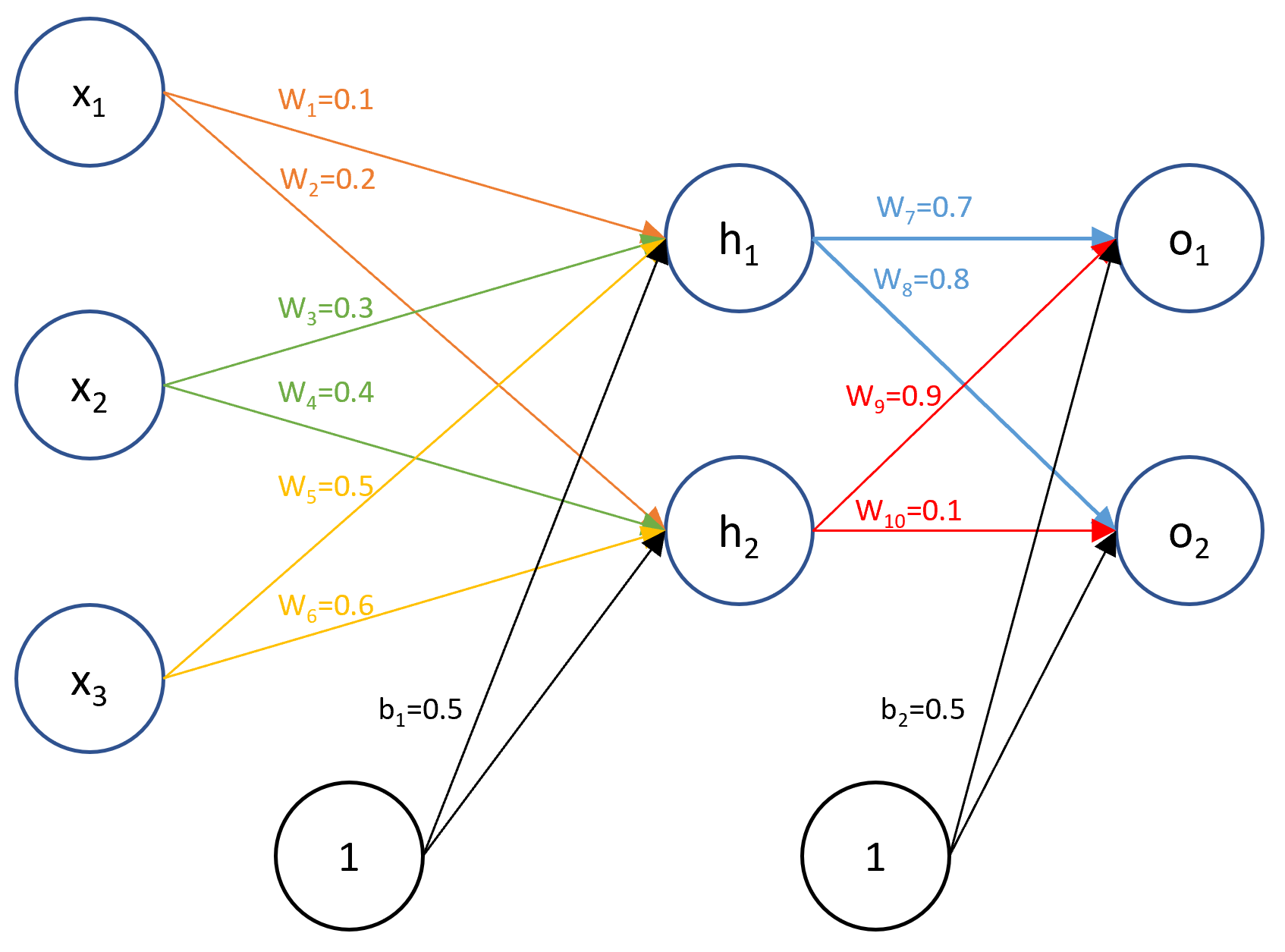
A neural network is actually a weight matrix, assume we have x as input, and the output is o, and we only have 1 hidden layer.
 |
| Neural Network |
The forward function is:
ZlXl−1=WlXl−1+bl=fl(Zl−1)
where:
- Zl is the input before activation functions
- Xl is the output of neurals (after activation)
- fl is the activation function.
Steps to train the neural network:
- Initialize the weights
- Forward: Calculate o with w,b
- Back-propagation: Calculate the derivate of loss function
- Iterate until loss below certain value
Assume:
x1=1,x2=4,x3=5,y1=0.1,y2=0.05
Activation function: fl(x)=σ(x)=1+e−x1
Loss function: L(y^,y)=21∑im(yi^−yi)2
Use the picture above.
Forward:
Zh1h1Zh2h2Zo1o1Zo2o2=w1∗x1+w3∗x2+w5∗x3+b1=4.3=fl(Zh1)=0.9866=w2∗x1+w4∗x2+w6∗x3+b2=5.3=fl(Zh2)=0.9950=w7∗h1+w9∗h2+b2=5.3=fl(Zo1)=0.8896=w8∗h1+w10∗h2+b2=1.3888=fl(Zo2)=0.8004
Then o1,o2 is our predictions for y1,y2 at the first time. We use back-propagation to optimize:
Back-propagation (only use w1 as an example):
∂w1∂L=∂o1∂L∗∂w1∂o1+∂o2∂L∗∂w1∂o2=∂o1∂L∗∂zo1∂o1∗∂w1∂zo1+∂o2∂L∗∂zo2∂o2∗∂w1∂zo2=∂o1∂L∗∂zo1∂o1∗∂h1∂zo1∗∂zh1∂h1∗∂w1∂zh1+∂o2∂L∗∂zo2∂o2∗∂h2∂zo2∗∂zh2∂h2∗∂w2∂zh2
From the formula we could see, if the derivate of loss function is less than 1, then after several multiplies the final result would be very small.
Ref: https://www.anotsorandomwalk.com/backpropagation-example-with-numbers-step-by-step/
Gradient Exploding & Gradient Vanishing
Why do we have thus problems?
Back propagation computes the gradient by chain rule. From the back propagation formula, we could see if the number of hidden layers is large, then the result would involve many intermediate gradients. And if the intermediate gradients are below 1, then the products of them would decrease rapidly, thus the gradient would vanish. On the other hand, if the gradients are all above 1, then the product would increase rapidly, so the final gradient would explode.
How to deal with gradient exploding?
To deal with gradient exploding, we can use a gradient clip method. When the gradient is above the threshold, then:
g=∣∣g∣∣∣∣Threshold∣∣∗g
How to deal with gradient vanishing?
- Model architecture: use LSTM, GRU.
- Residual: Add residual into the network
- Batch Normalization: TODO
- Activation function: use ReLU instead of sigmoid
Convolutional Neural Network (CNN)
@TODO
Recurrent Neural Network (RNN)
Sometimes the output of the neural network is not only related to input, but also related to current state (output from last time period)
Vanilla RNN
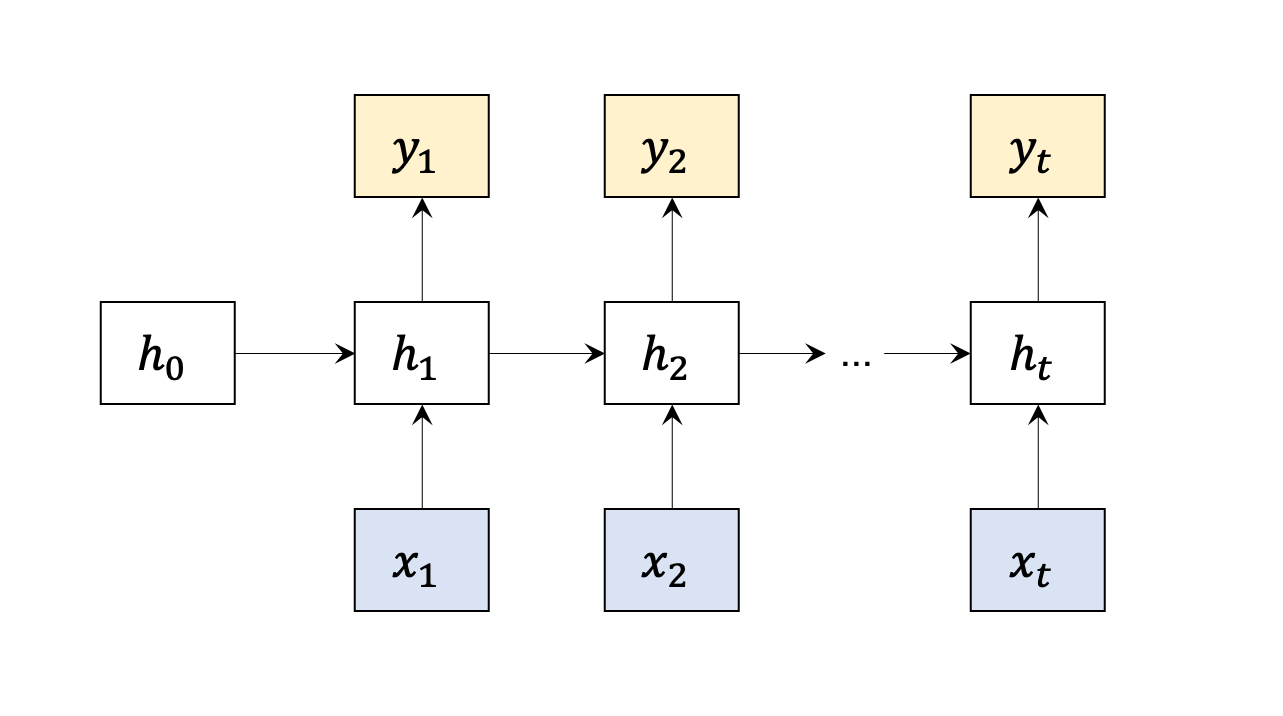 |
| vanilla rnn |
Forward:
{htyt=fh(WxX+Whht−1+bx)=fy(Wyht+by)
Note: Wx,Wh,Wy doesn’t change accroding to t, that’s called weight shareing.
Back-propagation:
∂Wh∂L=∂y1∂L∗∂wh∂y1+∂y2∂L∗∂wh∂y2+⋯+∂yt∂L∗∂wh∂yt
Sometimes to simplify calculation process, we would use a cutoff to shorten the window.
Different Architectures for Different Applications
ref: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks
| Type of RNN |
Illustration |
Example |
| one-to-one, Nx=Ny=1 |
 |
Traditional neural network |
| 1-to-many, Nx=1,Ny>1 |
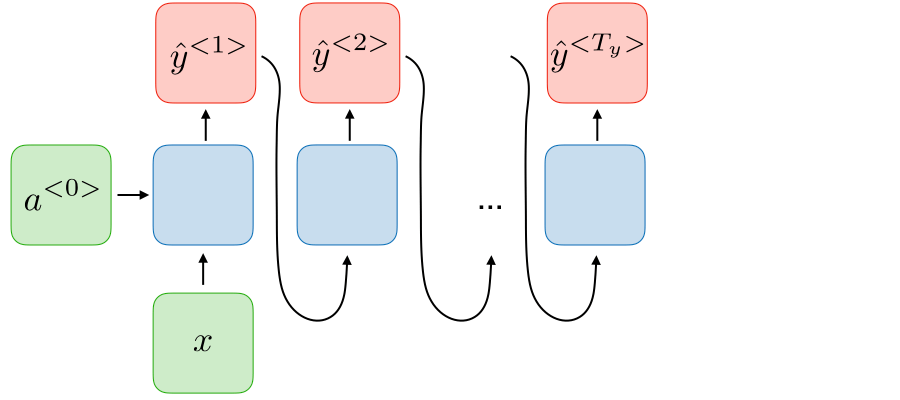 |
Music generation |
| many-to-1, Nx>1,Ny=1 |
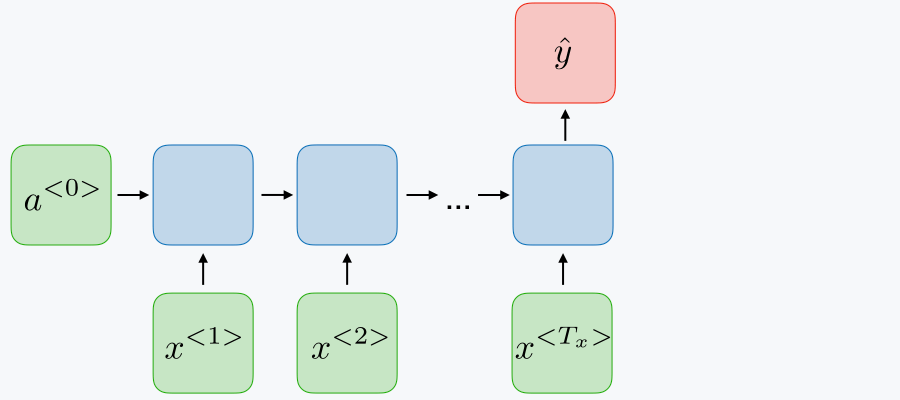 |
Sentiment classification |
| many-to-many, Nx=Ny |
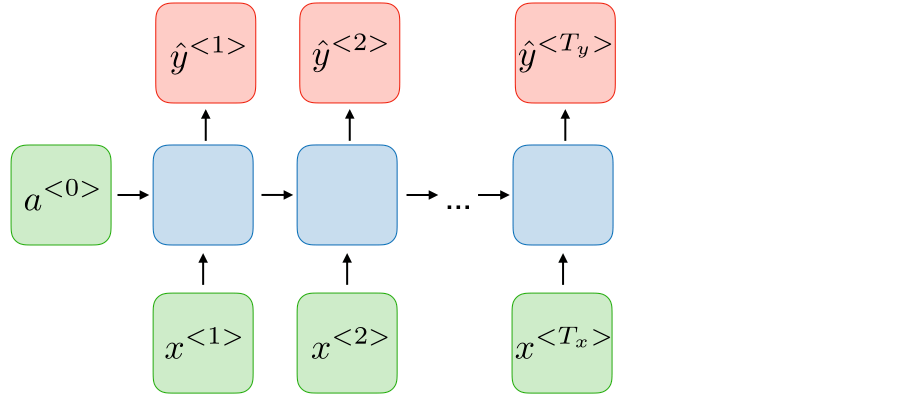 |
Name entity recognition |
many-to-many, Nx=Ny
encoer-decoder
seq2seq |
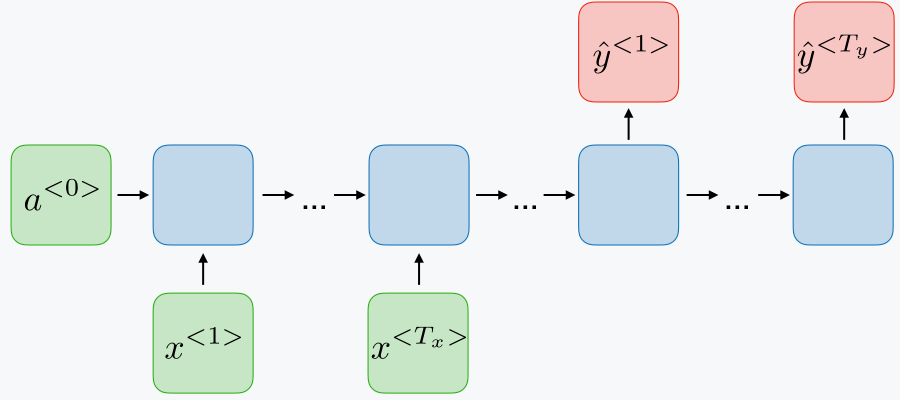 |
Machine translation |
RNN & Gradient Vanishing
For rnn, the gradient vanishing problem is even more severe, because usually the length of sequence is large.
Long Short Term Memory/LSTM
In vanilla RNN, ht is changing all the time, and it’s only based on the previous state, like a short memory. So here in LSTM, we introduce a cell ct to use longer memories (long short memory).
To avoid gradient vanishing/gradient exploding problem, LSTM introduce 3 gates: forget gate ft, input/update gate it, output gate ot.
Core idea of LSTM:
- Output ht is based on cell ct, that is: ht=ot⊗tanh(ct)
- Cell: ct=it⊗tanh(Wc[xt,ht−1]+bc)+ft⊗ct−1
Where:
- ⊗ is the outer product, multiply elementwise
- tanh(x) is the activation function here, because its derivative is larger. Could be replaced with ReLU here.
- The gates are also calculated by xt,ht:
ftitot=σ(Wf[xt,ht−1]+bf)=σ(Wi[xt,ht−1]+bi)=σ(Wo[xt,ht−1]+bo)
here we use σ because σ has a value of [0,1], which is “gate”.
4. The number of trainable parameters is related to input dimension and hidden layers, which is: (input_dim + hidden_unit + 1) * hidden_unit * 4
Proof: Trainable parameters come from 4 parts: 3 gates and the neural network. Since the inputs of the networks are concatenation of xt and ht, the dimension of the concatenated vector is 1 x (input_dim + hidden_unit). And we have 1 dimension for b, so for one part, the dimension is (input_dim + hidden_unit + 1) x hidden_unit, times 4 we get the final answer.
Gated Recurrent Unit/GRU
In LSTM, we have redundant gates ft and it. So instead of using 3 gates, we only use 2 gates in GRU, reset gate rt and update gate ut.
Output ht:
ht=ut⊗ht−1+(1−ut)⊗tanh(Wc[xt,rt⊗ht−1]+bc)
Similar to LSTM, ut and rt are also calculated by ht,xt:
utrt=σ(Wu[xt,ht−1]+bu)=σ(Wr[xt,ht−1]+br)