Other Things about ML - 2
Sampling
Common Down-sampling Methods
Sampling without replacement, in which a subset of the observations are selected randomly, and once an observation is selected it cannot be selected again.
Sampling with replacement, in which a subset of observations are selected randomly, and an observation may be selected more than once.
If we have m samples, and we do this sampling for m times, after choosing one item, we put it back. Then the sample size would be 63.2% of the original set.
Math details:
The probability of not being chosen is , so the probability of not chosen after m times is , if m is large enough, then we have:
Selecting a stratified sample, in which a subset of observations are selected randomly from each group of the observations defined by the value of a stratifying variable, and once an observation is selected it cannot be selected again.
Upsampling/Oversampling
SMOTE (Synthetic Minority Oversampling Technique)
Synthesize samples for the minority class.
Assume we need to oversample by N, then the steps are:
- Select 1 minority sample and find its knn.
- Randomly choose N nodes from k neighbors.
- Interpolate the new synthetic sample.
- Repeat 1-3 for all samples in minority class.
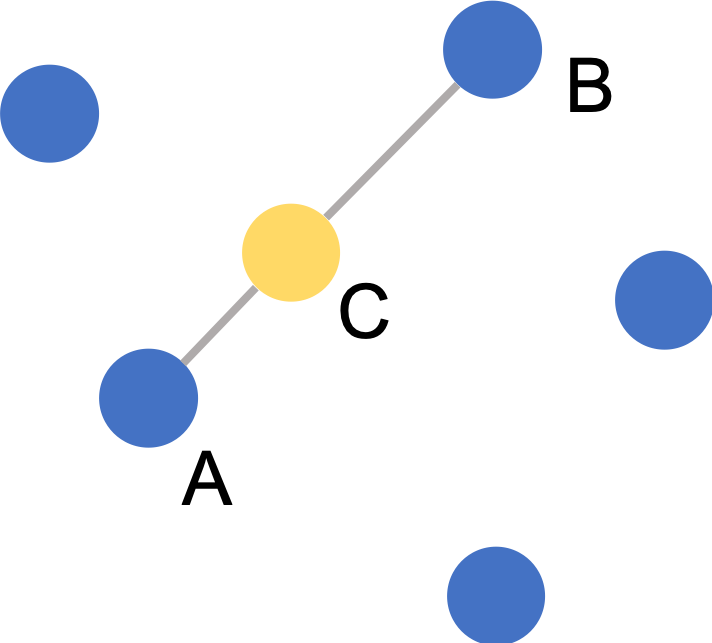
Interpolate as follows:
 |
|---|
| SMOTE |
Node C is synthesized based on the difference between node A and node B. The synthetic nodes are always in the same direction of its base nodes.
ANN (approximate nearest neighbor)
Common ann algorithms: trees, hashes, graphs
Tree-based: Kd-tree
Hash-based: LSH
Graph-based: HNSW
Ref: Similarity Search
 |
|---|
| Graph Search |
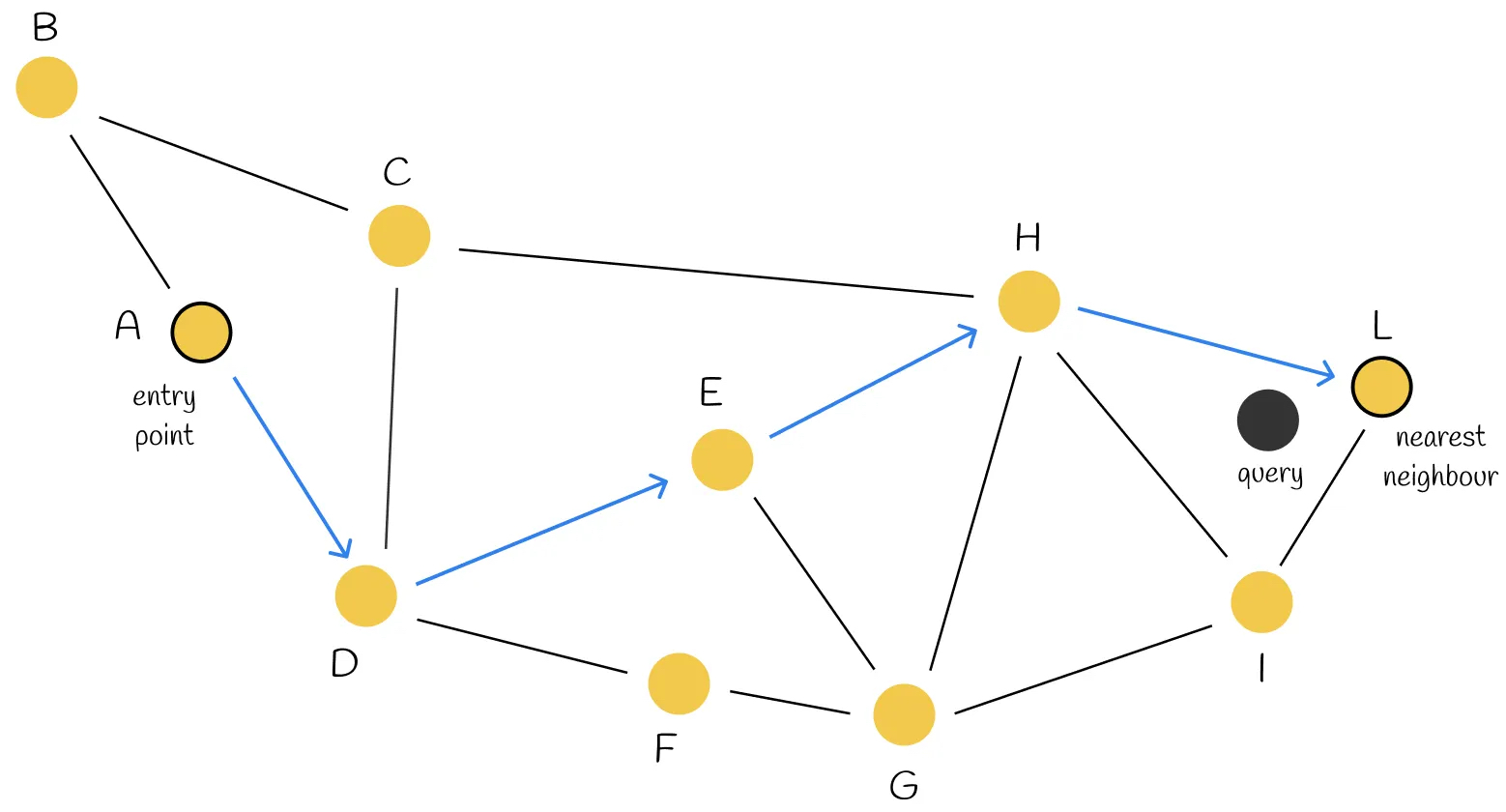
Intrinsic search: start with A, and then iterate all its neighbors to find the nearest one to query. Then move to the nearest neighbor. Repeat this process until there is no neighbor nodes that are closer than the current node. The current node is returned as the result.
Questions:
- What if there’s some nodes that have no neighbors?
- If we want to find the nearest 2 nodes for query, and these 2 nodes are not connected, then we need to run the whole graph twice, which costs lots of resources.
- How to build the graph? Does node
Greally need those neighbors?
Answers:
- When building graph, make sure that every node has at least 1 neighbor.
- When building graph, make sure that if 2 nodes are close enough, they must have an edge.
- Reduce the number of neighbor as much as possible.
How to build a graph, see NSW method.
NSW
In order to build a graph, firstly shuffle data points and then insert the nodes one by one.
When inserting a new node, link it with nearest M nodes.
Long-range edges will likely occur at the beginning phase of the graph construction.
HNSW
 |
|---|
| HNSW Search |
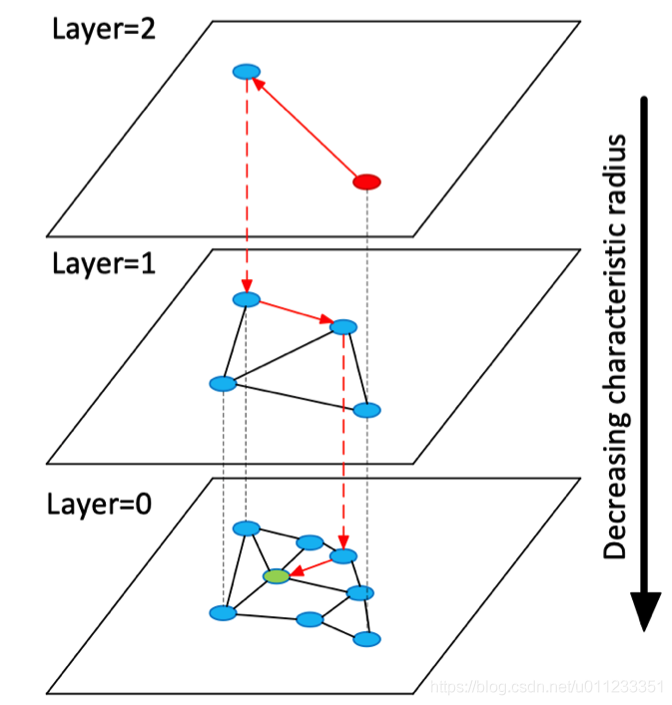
Build Graph: Use a parameter to decide whether this node needs to be inserted into certain layer. And the node is inserted into its insertion layer and every layer below it.
Search Graph: Start with top layer, find the nearest node greedily, and then go to lower layer. Repeat until the 0 layer.
K-Fold Cross Validation
@TODO
Normalization
The goal of normalization is: transform features to be on a same scale.
For batch Normalization and layer normalization, they are used in deep learning models, see details here.