Other Things about ML - 1
Entropy
Entropy
In information theory, entropy is the amount of uncertainty, assume the probability distribution of a single discreate random variable x is , then the entropy of x is:
Note: Entropy cares only the probability distribution of a variable, it has nothing to do with the value of the variable.
Joint Entropy
For 2 discreate random variables and , assume the joint probability distribution is , then the joint entropy is:
Properity
- Non-negativity
- Greater than individual entropies:
- Less than the sum of individual entropies:
Conditional Entropy
The conditional entropy quantifies the amount of information needed to describe the outcome of a random variable given that the value of another random variable is known.
Properity
- if and only if the value of
Yis completely determined by the value ofX - if and only if
YandXare independant random variables. - Chain rule: Joint entropy .
Proof:
Cross Entropy
Cross entropy could measure of difference between 2 probability distributions p and q over the same underlying set of events.
Difference from joint entropy:
- Joint entropy is 2 random variables over 1 probability distribution
- Cross entropy is 1 random variable over 2 different probability distributions
p,q
Cross entropy is widely used as a loss function in ML because of its relationship with KL divergence.
KL Divergence/Relative Entropy
KL divergence is the measure of how one probability distribution P is different from a second, reference probability distribution Q, or the loss you would get when you want to use p to approxmate q.
Note:
- Since KL divergence is the measure of distance between 2 probability distributions, it’s range is . if and only if
p=q. - is converx in the pair of probability measures
p,q.
Mutual Information/MI/Information Gain
Mutual information is a measure of the mutual independence between two variables. Eg: is the result of a dice, and is whether is odd or even. So from we could know something about .
It’s defined as:
Or it could be defined as:
It’s also known as the information gain, which is defined as:
Performance Evaluation
Confusion Matrix
| ground truth / predictions | positive | negative |
|---|---|---|
| positive | TP(true positive) | FN(false negative) |
| negative | FP(false positive) | TN(true negative) |
Precision
Precision is the fraction of relevant instances among the retrieved instances, which is:
Recall
Recall is the fraction of relevant instances that were retrieved.
Accuracy
Accuracy is how close a given set of observations are to their true value, it treats every class equally.
F1
F1 is the harmonic mean of precision and recall.
F1 is the special condition of , the higher is, the more recall is important over precision.
For F-score, it’s calculated based on predicted classes, instead of probabilities.
Use it for classification problems.
Support
TODO
ROC/AUC
A ROC space is defined by FPR(false positive rate) and TPR(true positive rate) as x and y axes, respectively, which depicts relative trade-offs between true positive (benefits) and false positive (costs).
FPR: defines how many incorrect positive results occur among all negative samples available during the test. Or how many negative samples that are higher than the gate are in the all negative samples.
TPR: defines how many correct positive results occur among all positive samples available during the test. Or how many positive samples that are higher than the gate are in the all positive samples.
How to draw ROC curve?
Use probability from the model to rank from large to small, then use the maximum prob as the gate, all samples above the gate are positive, others are negative. Change the gate and calculate the FPR(x) & TPR(y), then draw the line.
AUC is the ability of model to rank a positive sample over a negative sample
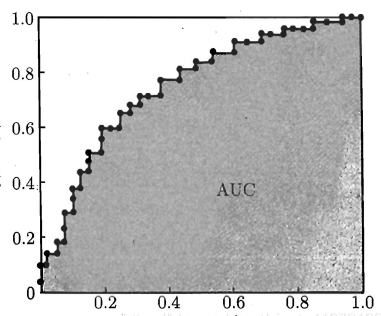 |
|---|
| AUC |
Special positions
- means classify all the samples to negative, so the FPR=0 and TPR=0
- means classify all the samples to positive.
Use the sum of many discreate trapezoidals’ areas to approximate AUC, assume we have samples, then AUC is:
Use it for ranking problems
Advantage:
- Don’t need to decide a gate value for positive and negative samples.
- Not sensitive to positive and negative samples, only care about the ranking.
Disadvantage:
- Ignore model’s ability to fit the actual probability. For example, if the model give all positive samples prob as 0.51, and all negative samples as 0.49, auc is 1, but the model is underfitted because of the cross entrophy loss is huge.
- Not a good indicator for precision and recall. Sometimes we care only precision or recall.
- Don’t care the ranking between positive samples and negative samples.
gAUC/group AUC
@TODO
prAUC
NDCG
Loss Function
Suitable for Classifications
Cross Entropy Loss
Cross entropy is use the estimated data distribution to approximate the true data distribution , that is:
So accroding to this, the cross entropy loss function is:
Hinge Loss
TODO
Suitable for Regressions
Mean Square Error/MSE/L2
Mean Absolute Mean/MAE/L1
Huber Loss
 |
|---|
| Huber Loss |
Huber loss (green) and squared error loss (blue)
Huber loss is a combination of L1 loss and L2 loss.
- Advantage: Optimize L1 & L2 loss’s disadvantages. (When the loss is near 0, use L2 loss. When it’s away from 0, use L1 loss.)
- Disadvantage: need to tune .
Suitable for Classification + Regression
- Advantage: very straightforward
- Disadvantage: discreate; derivative equals to 0, thus hard to optimize
Optimization Algorithms
Gradient Descent & its twists
Steps:
- Determine the learning rate.
- Initialize the parameters.
- Choose samples for calculating the gradient of the loss functions.
- Update the parameters.
Note: GD could gurantee the global optimal for convex functions, and local optimal for non-convex functions.
 |
|---|
| Convex Function |
Batch Gradient Descent
Calculate the gradient on all the data, then update the parameters.
Stochastic Gradient Descent/SGD
Calculate the gradient based on 1 single sample, then update the parameters.
Advantage:
- Fast, could be used for online learning
- Loss function might fluctuate
- Glocal optimal not guranteed (could be solved by decreasing learning rate with an appropriate rate)
Mini-batch Gradient Descent
Calculate the gradient on all the data from the batch, then update the parameters.
Usually we use as the range for batch size, since mini-batch is very common, in most cases, the sgd in python libraries is actually mini-batch.
where: is the learning rate, and the batch size is
Note:
- It needs to tune manually.
- Global optimal not guranteed.
- If the data is sparse, we might want to update the weights more for those frequent features, and less for those less frequent features.
Tips:
- Shuffle the training data before using this.
- Do batch-normalization for each mini-batch.
- Increase learning rate when batch size increased.
TODO