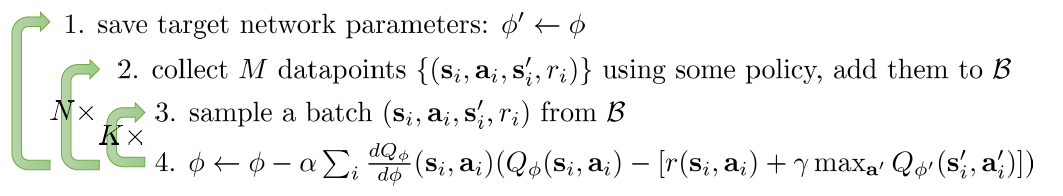Because all the samples we collected are happened sequentially, they are similar and strongly correlated, and the target value is always changing.
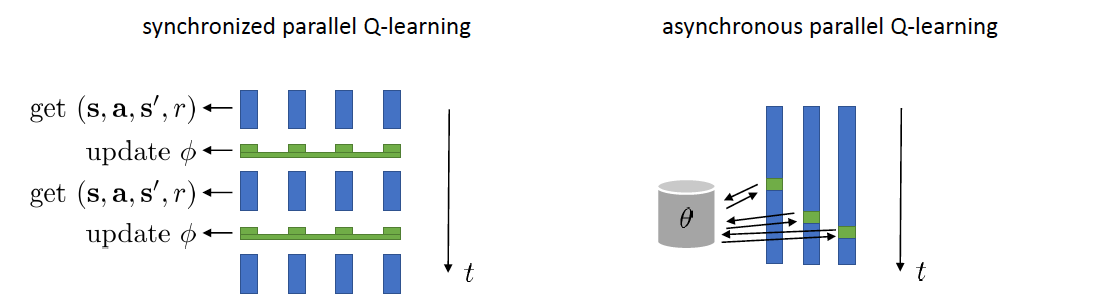
synchronized/asynchronized parallel Q-learning
To solve this problem, we could use synchronized parallel Q-learning or asynchronized parallel Q-learning as used in actor-critic:
replay buffer
Use replay buffers to generate data samples, we now have:
This way samples are no longer correlated, and due to multiple samples in one batch, we have low-variance.
In the end, we get the full q-learning with replay buffer:
Large replay buffer helps to stablize
Target Network & Predict Network
In q-learning, when we need to update ϕ, we’ll need to calculate:
ϕ←ϕ−αi∑∂ϕ∂Qϕ(si,ai)(Qϕ(si,ai)−no gradient through target value[ri+γa′maxQϕ(si′,ai′)])
The target value every step, so the network is hard to converage, we’ll need to use another less-changed network.
If we take K=1 then we’ll have DQN:
take some action ai and observe (si,ai,si′,ri), add it to B, the actions were generated by ϕ and we might use epsilon-greedy here.
sample mini-batch (sj,aj,sj′,rj) from B uniformly
compute yj=rj+γmaxaj′Qϕ′(sj′,aj′) using target network Qϕ′
ϕ←ϕ−α∑j∂ϕ∂Qϕ(sj,aj)(Qϕ(sj,aj)−yj)
update ϕ′: copy ϕ every N steps
This way would lead the step right after the update of ϕ′ to be only 1 step older, and the step right before to be the oldest. We could use Polyak Averaging (an optimization technique that sets final parameters to an average of recent parameters visited in the optimization trajectory) to be fair to every step.
When update ϕ′, now we do:
ϕ′←τϕ′+(1−τ)ϕ
For a more general view, q-learning with replay buffer and target networks is as follows:
Improve Q-learning
Problem: Overestimate the Q Value
Q-learning tends to overestimate the q value, because we calculate yj as follows:
yj=rj+γhere’s the problemaj′maxQϕ′(sj′,aj′)
Because E[max(X1,X2)]≥max(E[X1],E[X2]), and Q←r+γE, the q-learning will overestimate the true q value.
Solution: Double Q-learning
Note that we select action a′ from Qϕ′(s′,a′), and we also estimate q-value using it, so:
a′maxQϕ′(s′,a′)=a′maxvalue also from Qϕ′Qϕ′(s′,action selected from Qϕ′a′argmaxQϕ′(s′,a′))
If Qϕ′(s′,a′) has noise, it would be multiplied. Thus we use two separate networks to choose the action and evaluate value.
In practice, we already have target network and predict network, so we will use them as ϕA,ϕB
So a double q-learning will be:
y=r+γa′maxQϕ′(s′,a′argmaxQϕ(s′,a′))
Note we use predict network Qϕ to choose actions, use target network Qϕ′ to evaluate the value.
Overall this double-q network helps a lot in practice, and it has no downsides.
Multiple Steps
Since we calculate q-learning target by:
yj,t=rj,t+γaj,t+1maxQϕ′(sj,t+1,aj,t+1)
The rj,t is the only values that matter if Qϕ′ is bad, and Qϕ′ is the only values that matter if Qϕ′ is good. So if our Qϕ′ is bad at first, we may get stuck. If we calculate rewards at multiple steps, we could avoid this problem.
In practice, just ignore this restriction and apply it to off-policy, it still works well somehow…
Countinuous Actions
To find the a′argmaxQϕ′(s′,a′) is easy when actions are discreate, but when actions are continuous, it would take much time.
Approximate
We could approximate the a′argmaxQϕ′(s′,a′) by using monte-carlo like methods:
amaxQ(s,a)≈max{Q(s,a1),Q(s,a2),…Q(s,an)}
(a1,a2,…,aN) are sampled from some distribution
Works well for about 40 dimensions.
Choose Easily Maximizable Q-functions
At the cost of reducing the representation capacity of q-function, we could make aargmaxQ and maxaQ very easy, for example we could use NAF/Normalized Advantage Functions
Qϕ(s,a)=−21(a−μϕ(s))TPϕ(s)(a−μϕ(s))+Vϕ(s)
and we get:
aargmaxQϕ(s,a)amaxQϕ(s,a)=μϕ(s)=Vϕ(s)
ddpg: learn an approximate maximizer
train a network μθ(s) so that μθ(s)≈aargmaxQϕ(s,a)
ddpg:
take some action ai and observe (si,ai,si′,ri), add it to B, the actions were generated by ϕ and we might use epsilon-greedy here.
sample mini-batch (sj,aj,sj′,rj) from B uniformly
compute yj=rj+γQϕ′(sj′,μθ′(sj′)) using target network Qϕ′ and μθ′
ϕ←ϕ−α∑j∂ϕ∂Qϕ(sj,aj)(Qϕ(sj,aj)−yj)
θ←θ+β∑j∂θ∂Qϕ
update ϕ′,θ′: eg Polyak averaging
Implement
Adam as the optimizer works better.
Remember to run using different random seeds.